【HTML】Twitterでよく見る絵文字や顔文字の追跡;twemojiのサンプル実装方法について
Twitterでよく出てくる「絵文字」「顔文字」その他「不思議な文字」の正体を追跡する暇つぶしコーナー
主にtwemojiの簡単な実装方法の紹介(むしろその程度にしか知らん)と、絵文字や顔文字に関する情報の収集や整理等。
Twitterにおいて、1文字分の枠で、色つきで表現される「顔文字」とか「絵文字」は、
twemojiというAPIを通して画面に表示されているようだ。
例えば個人的によく使う「😂」は、(なんとなく使い勝手がいいんだw)
Twitter上の表示は「涙流しながら笑ってる顔」で表現されているが、
文字としてはUnicodeでいうところのU+1F602;FACE WITH TEARS OF JOYで定義されている。
これは、twemojiを使わない場合、かろうじて「笑ってる顔」とわかる程度に、図形というか、記号というか、そんな風に見えるが、
twemojiを使うと自動で「絵」っぽく変換してくれる。
例としてU+1F602について、twemojiの有無ブラウザの表示をしてみると
※情報を正確にするため、どっちも画像にしてある(文字ではない)。
twemmojiなしtwemmojiあり
twemojiを使う(使って文字をTwitterっぽく表示させる)場合は、
HTMLソースコードのhead部内に以下のscriptタグを差し込み
<script src="https://twemoji.maxcdn.com/2/twemoji.min.js?2.3.0"></script>
HTMLソースコードのbody終了直前に以下のようなコードを差し込むだけでいい(めっちゃ簡単)。
<script> twemoji.parse(document.body); </script>
正確に言うと「twemoji.parse(document.body);」を差し込んだ箇所より手前を全てtwemoji化するみたいなので、
bodyの途中にいれても、ページ全体に適用されないだけで、差し込んだ箇所までは効果を発揮する。
試しに以下のようなソースをHTMLで保存してブラウザで表示してみると。
<html> <head> <meta charset="UTF-8"> <script src="https://twemoji.maxcdn.com/2/twemoji.min.js?2.3.0"></script> <title>twemoji test</title> </head> <body> テストです。<br/> <br/> U+1F602:'FACE WITH TEARS OF JOY';😂<br/> <br/> <script> twemoji.parse(document.body); </script> </body> </html>
俺のパソコンのブラウザで表示したときの表示結果はこれ↓
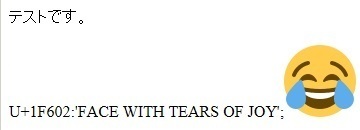
ソースコードの赤太字部分(の、特にHTML文字参照で記述している部分「😂」にあたる部分)が、
twemojiで絵で表現されているのがわかる。
ちなみにtwemojiなしだと↓みたいになる。
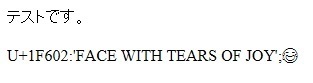
U+1F602と同様の種類の「顔文字」はUnicodeとしてはU+1F600~U+1F64Fの範囲に定義されていて、
装飾される前の純粋なフォント(↑でいうところのtwemojiなし状態)をWikipediaのUnicodeの一覧ページで確認することができる。
コード的にはサロゲートの範囲なので若干扱いづらいところはあるが、
いずれにしてもUnicodeにちゃんと定義された「文字」である。
ちなみに、基本多言語面内(サロゲートじゃない範囲内)では、
U+2xxx系に「絵文字」という文字群が定義されている。
2000年前後一時的にdocomoユーザだった(当時は中学生だったか高校生だったか…)のだが、
そのとき見た覚えのある絵文字があって懐かしい。
当時は全く意味わかってなかったが♒(U+2652;AQUARIUS)をなんでだかよく使っていた記憶がある。
(docomoだと赤かったような)
なお、このあたりの文字も、twemojiによる装飾の対象になっているようだ(少なくともU+2652はtwemoji化した)。
恐らく上記のリンクの「絵文字」にあたるものサロゲートのものを含めて全てtwemojiで変換される。
一つのコードポイントを統一された「絵」に強制的に置き換えることで、
異なる環境やユーザ間で表示の不整合が発生するのを回避している。いい仕組みだね。
「1」みたいな数字を、□で囲ってるような形の文字を、
アカウント名としてつけている人をたまーに見かけるが、
これは恐らくUnicodeの文字合成を使って実現されている。
例えば以下の文字は恐らく数字の「1」が□で囲まれた形で表示されるはずである。
1️⃣
※環境によるっぽい。IEだとうまく囲われない。Chromeだと囲われた。フォントとかにも依存するようだ。
Unicodeには、物理的に異なる複数の文字を1つの文字として表現する(「合成」というらしい)考え方があり、
この「囲み文字」もそれの一種である。
↑の「1️⃣」は、1文字に見えるが、正確には以下の3つのコードポイントで表現されている。
| U+0031 | U+FE0F | U+20E3 |
| 1 | ️ | ⃣ |
1つ目のU+0031は何の変哲もないマジで普通の半角数字の「1」。
2つ目のU+FE0Fは「異字体セレクタ」といって、
そのコードの一つ前の文字の「スタイル」を指定する特殊な記号である(その意味では恐らく制御文字に近いはず)
U+FE0Fは「絵文字スタイルにしろ」という指示コードであり、
後ろの囲い文字と合わせて一つの絵文字を形成している。
3つ目のU+20E3もUnicodeで合成されることを前提に定義された囲い記号である。
3つあわせて初めて囲い数字の1になる。
どちらかというと「ザ」や「パ」のように、
濁点付の文字を2つのコードポイントで表現できる(合成できる)というほうが正規(?)の仕様で、
こういった使い方は「ついで」のようなイメージがあるが、
とにかくUnicodeの合成の仕様を使ってこれが可能ということである。
ちなみに半角数字以外だとうまい具合に囲われない。
半角英字、半角カナもだめ。
全角はもちろんだめである。
また、「10」のように、半角数字2つを指定しても、
合成されるのは「0」のほう(異字体セレクタの手前にいる文字)だけになる。
カタカナやひらがなを囲い文字として指定して、
囲いの外に文字が出てしまってるアカウント名の人をどっかで見た記憶があるが、
それはこうした理由によるものと思われる。
ただフォントの指定とか(いわゆる環境に依存した設定)できれいに見える可能性もあると思うので
「俺が見たらうまく囲われていない」だけでその人からはうまく囲われている可能性もある。
ちょっとだけ例を挙げてみよう。
以下のようなソースをHTMLで保存してブラウザで開いてみた(Chromeである)。
<html> <head> <meta charset="UTF-8"> <title>kakomi test</title> </head> <body> 囲み文字のテストです。<br/> <br/> 「1」の囲み文字↓<br/> 1️⃣<br/> 「9」の囲み文字↓<br/> 9️⃣<br/> 「10」の囲み文字↓<br/> 10️⃣<br/> 「1」の囲み文字↓<br/> 1️⃣<br/> 「A」の囲み文字↓<br/> Aamp;#xFE0F;⃣<br/> 「A」の囲み文字↓<br/> A️⃣<br/> 「ア」の囲み文字↓<br/> ア️⃣<br/> 「あ」の囲み文字↓<br/> あ️⃣<br/> <br/> </body> </html>
結果はこれ↓

なお、この辺は以下のURLを参考にさせていただいた。
https://pullup.net/technical/unicode/uni.html
https://qiita.com/_sobataro/items/47989ee4b573e0c2adfc
あとは昔からある、複数の記号文字を連続してくっつけてることで顔面っぽく見せる顔文字。
これは↑までで紹介したテクニック的なものと違って、
文字の純粋な字体を使った表現技法(AAに近い)なので、
その辺の知識が浅い俺のようなシステム屋的には比較的馴染み易い(わかりやすい)。
個人的には
(´・ω・`)ショボーン
とか
(`・ω・´)シャキーン
とかをよく使う。
これらの顔文字には別にそこまでむずかしい文字は使われていないが、
最近のこのテの顔文字は進化していて、
全く想像がつかなかった字体の字を見つけてくっつけている。
以下にいくつか例を挙げる。
No顔文字説明
| 1 | ( ಠ_ಠ) | フォントによると思うが、目を見開いてどこかをじっと見つめている様子の顔になる。 20世紀ロックバンド「ストレイテナー」のドラマー・ナカヤマシンペイ氏がよく使ってる印象。 重要なのは目の部分にあたる「ಠ」で、コードポイントはU+C0A0. ブロック的には「ハングル音節文字」という範囲に定義されているようだ。 英語のページに解説がのっているが、なんだかよくわからん。韓国の音節文字のようだ。 |
| 2 | 。゚( ゚இ‸இ゚+)゚。 | 多分泣きわめいてる様子を表した顔文字(歓喜によるものか悲劇によるものかはわからんがどっちにも使える印象)。 やはり重要なのは目にあたる部部分だが「இ」で、コードポイントはU+0B87 ブロック的には「タミル文字」という範囲に定義されているようだ。 「タミル語とは南インドのタミル人の言語」とのこと。全くわからん。 一応「アジアの言語」の一つであるようだ。 どこから見つけてきたのか感心するレベルである。 |
| 3 | _:(´ཀ`」 ∠): | 血を吐いて倒れている様子を表す顔(体?)文字。 好きなバンドのライブのチケットが当選して「もう死んでもいい」というほど限界突破した歓喜であったり 「仕事がやってられねえもう死ぬ」というほど底辺をうろつく憂鬱さであったり 何かその辺諸々の極端な感情表現に使われているイメージ。 個人的に女性が使っている印象が強い。 重要なのは血を吐いてる口にあたる部分「ཀ」で、コードポイントはU+0F40 ブロック的には「チベット文字」である。 ここで表示されている文字が真っ赤で怖い。 |
| 4 | (;´༎ຶД༎ຶ`) | 血の涙を流している様子を表す顔文字。 こっちはどちらかというと「血の涙が流れるほど嬉しい」というような 感極まった嬉しさを表現するときに使われるイメージ。 重要なのは目の部分だが、 プロポーショナルフォントだと一見1文字に見えるが、実際には2文字が隣接している。 1文字目が「༎」でコードポイントはU+0F0E No.3と同様チベット文字。 2文字目が「ຶ」でコードポイントはU+0EB6 これはブロック的には「ラオス文字」の範囲内にいる。 |
なんか他にもあった気がするが一旦この辺までとしておこう。
こうして見ると、パッと見なじみのない記号のような文字が顔文字に使われている場合、
そこにアジア圏の文字が使用されていることは多いようである(韓国、南インド、チベット、ラオス)
また、表示に際しては、フォントに依存するところも強いため、
フォント側の加工次第では、今まで全然顔文字との関連がなかった文字が、
急に顔文字の素材として昇華(?)することも考えられる。
探せばもっといろいろ「顔文字の素材」があるのかもしれないね。