【Java】サロゲートペアを出力したり中身を見たりする方法について
Javaでサロゲートぺアを出力したりコードポイントを見たりする方法について
Unicodeの基本多言語面(U+0000~U+FFFF)の文字については、
char型の変数に対象のコードポイントを示す値をセットすれば、
それをそのままUnicodeの1文字として扱うことができる。
しかしサロゲートはchar型で扱える値を超えている(U+10000~)ため、
基本多言語面内の文字と同じ要領でchar型変数に定義するとコンパイルエラーになる。
例えば
char ch = '\u3042'; // 「あ」を示す
は、コンパイルが通るし「あ」1文字として扱う分にも問題ないが
char ch = '\u29e3d'; // 本来なら「𩸽」(ほっけ)を示すが…
は、コンパイル自体が通らない。
じゃあどうやってサロゲートのコードポイントを変数値として示すか、というと、
int型を使うことなる。
int cp = 171581; // 」「𩸽」(U+29E3D)のコードポイントの10進数値 String str = new String(new int[]{cp},0,1);
Stringのコンストラクタに、
int型の配列と、
配列の中のどこからどこまでを文字列化するかというのを引数で渡すのがあり、
このうち「int型の配列」の要素に、Unicodeのコードポイントを示す数値を引き渡すことで、
サロゲートの文字化(String化)が可能となる。
↑の例では1文字だけを対象に文字化している(渡してる配列も1要素だけ)が、
配列の要素数を増やせば複数文字を連結して文字化することができる。
なお、Unicodeのコードポイントはふつう16進数で表記されている(U+FF0Dみたいに)ので、
int型にするために一度10進数に変換する必要がある。
(ただ、コードに素書きで16進数表記の数値書けたような記憶も薄らとある…
ググっても出なかったからないのかもしれないが)
JavaだとInteger#parseIntの第二引数に16を与えれば10進化できる。
String cpStr = "29e3d";
int cpDec = Integer.parseInt(cpStr , 16);
ちなみに、JavaDocのAPIにも書いてあるが、
↑に挙げたint型の配列を引数にとるStringのコンストラクタは、
Unicodeのコードポイント外の値をintで渡すとIllegalArgumentExceptionが発生する。
具体的には、
Unicodeはサロゲート含めてコードポイントの定義がU+10FFFF=1114111までなので、
これを超える値を渡すと例外が発生する。
同様に負数を渡しても例外が発生する。
char型には負数の範囲がない(U+0000は10新でも「0」)のでこういうことを考えなくて良かったのだが
まあ、下手に動いて変なコードにマッピングされるよりはいいのでこれはこれで頭の片隅に置いておく程度にする。
Javaのintの定義範囲はcharを包括しつつそれより広いので、
↑のコンストラクタを使った文字化のやり方は基本多言語面にも適用できる。
よって、これはUnicodeの文字を扱うやり方の一般系と言っていいと思う。
ただ16進数でビシッと1文字指定できるchar型のほうが直感的にわかりやすい(可読性が高い、と思う)のもあり、
単に「やり方として包括的にカバーできる」というだけで
「Unicodeの文字化」をするうえでこのやり方が毎回採用されるべきという感じもしない。
場面に応じて使い分ければいいと思う。
このやり方はUnicodeのコードポイントを指定して文字にするもので、
いわゆる「サロゲートペア」の各々2バイトの存在が文字化の過程で出てこない。
が、下記のやり方で、対象文字の「上位サロゲート」と「下位サロゲート」を取り出すことができる
int cp = 171581; // 」「𩸽」(U+29E3D)のコードポイントの10進数値 String str = new String(new int[]{cp},0,1); char[] chars = new char[2]; str.getChars(0,2,chars,0); System.out.println("HIGH_SURROGATE=" + Integer.toHexString(chars[0])); System.out.println("LOW_SURROGATE=" + Integer.toHexString(chars[1]));
String#getCharsメソッドで、引数に渡したchar型の配列に、その文字のchar値を取得してセットしてくれる。
サロゲートは上位と下位で2つのコードポイントから成るので、char型の配列を2として定義して引き渡す。
0番目(最初の要素)に上位サロゲートが、
1番目(次の要素)に下位サロゲートが
それぞれ入った状態になる。
例えば「𩸽」(U+29E3D)は、上位サロゲートU+D867、下位サロゲートU+DE3Dで構成されており、
↑のやり方でそれぞれのコードポイントを取得することができる。
このやり方を使って、追加多言語面の全てのUnicodeの「文字」について、
テキストファイルに出力してみたくなったので、とりあえずやってみた。
簡易的につくったプログラムはこれ↓
import java.io.*;public class SurrogateOutputTest {
private static final Object[][] SURROGATE_CODEPOINTS = new Object[][] { {"Supplementary Multilingual Plane" , new Integer(65536) , new Integer(131071)} // U+10000~U+1FFFF ,{"Supplementary Ideographic Plane" , new Integer(131072) , new Integer(196607)} // U+20000~U+2FFFF ,{"Tertiary Ideographic Plane" , new Integer(196608) , new Integer(262143)} // U+30000~U+3FFFF ,{"(未使用)" , new Integer(262144) , new Integer(917503)} // U+40000~U+DFFFF ,{"Supplementary Special-purpose Plane" , new Integer(917504) , new Integer(983039)} // U+E0000~U+EFFFF ,{"私用面" , new Integer(983040) , new Integer(1114111)} // U+E0000~U+EFFFF }; private static final String ENCODING_UTF8 = "UTF-8"; private static final File OUTPUT_DIR = new File("output_dir"); public static void main(String[] args) throws Throwable { try { execMain(); } catch(Throwable e) { e.printStackTrace(); } } private static void execMain() throws Throwable { System.out.println("★開始"); for (int i=0; i < SURROGATE_CODEPOINTS.length; i++) { Object[] objects = SURROGATE_CODEPOINTS[i]; String blockName = (String)objects[0]; Integer fromCodePoint = (Integer)objects[1]; Integer toCodePoint = (Integer)objects[2]; writeMain(i+1,blockName , fromCodePoint , toCodePoint); } System.out.println("★終了"); } private static void writeMain(int idx , String blockName,Integer fromCodePoint,Integer toCodePoint) throws Throwable { BufferedWriter bw = null; try { String outputFileName = lpadZeroStr(idx,3) + "_" + blockName.replace(" ","_") + ".txt"; File outputFile = new File(OUTPUT_DIR,outputFileName); bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outputFile),ENCODING_UTF8)); int fromCpInt = fromCodePoint.intValue(); int toCpInt = toCodePoint.intValue(); for (int cp = fromCpInt; cp <= toCpInt; cp++){ String codePointStr = Integer.toHexString(cp).toUpperCase(); String str = new String(new int[]{cp},0,1); char[] chars = new char[2]; str.getChars(0,2,chars,0); String highSurrogateCodePointStr = Integer.toHexString(chars[0]).toUpperCase(); String lowSurrogateCodePointStr = Integer.toHexString(chars[1]).toUpperCase(); bw.write(codePointStr + " " + highSurrogateCodePointStr + "," + lowSurrogateCodePointStr + " " + str); bw.newLine(); bw.flush(); } } catch(Throwable e){ throw e; } finally { if (bw != null) { bw.close(); } } } private static String lpadZeroStr(int num,int len) { String str = String.valueOf(num); int pad = len - str.length(); if (pad < 0) { return str; } else { StringBuilder sb = new StringBuilder(); for (int i=0; i < pad; i++) { sb.append("0"); } sb.append(str); return sb.toString(); } }}
実行環境に「output_dir」というディレクトリが必要だが、
実行するとその配下に、それぞれのブロック名ごとにファイルが出力される。
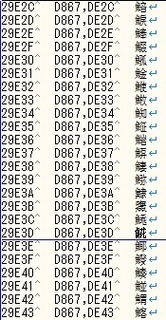
ファイルは以下の形式になる。
No項目名項目説明
| 1 | Unicodeコードポイント | Unicodeのコードポイント値。U+xxxxxのxxxxxにあたる値。 |
| 2 | 上位&下位サロゲートの コードポイント |
その文字の上位と下位のそれぞれのコードポイント値を 「,」(半角カンマ)で連結して並べて出力する。 |
| 3 | 文字 | コードポイントが示す文字そのもの。 |
一部抜粋して画面とったのがこれ↓
ちなみにWikipediaによれば、
U+30000 - U+3FFFFは”古代漢字や甲骨文字などが収録される予定”
U+40000 - U+DFFFFは”未使用(将来どのような目的で使用するのかすら決まっていない)。”
なので、この範囲にあたるコードポイントは出力したところで実質意味がない
(ただ一応、Unicodeコードポイント範囲内ってことで、Stringのコンストラクタは例外を発生させないようだ)。
また、
U+F0000 - U+10FFFFは拡張版の私用領域(いわゆるサロゲートの外字エリア)なので、
環境によって異なる文字が見える可能性がある。(が、このエリアに外字を登録する方法を俺は知らない…)
というわけで、サロゲートを全て出力することはできたわけだが、
実質ちゃんと「文字」として見えるのはそこまで多くはないようだ。
実際、日本語環境下で、単一の「文字」として気にすることになる可能性があるのは、
恐らくU+20000~U+2FFFFのどこかだと思われる。
(この範囲にJIS X 0213の第3水準・第4水準漢字の一部も収録されている)
一部絵文字などの表現にあたっては
合成用の指示記号が収録されているU+E0000~U+U+EFFFFなんかも気にする必要も出てくるが、
単一の文字として気に掛ける範囲ではないと思う。
個人的に、今までのシステム開発の経験上、
「UTF-8の全角文字は3バイト」という固定観念が生まれるほど、サロゲートに対するSEの認識は(俺を含め)低い。
また、3バイトの中でも、JISでいうところの第1水準・第2水準漢字までで充分であり、
そもそも第3水準・第4水準が必要になる場面がない(ないし、少ない)。
第3・第4も一部は基本多言語面にいることもあって実質そこまで困らないのだ。
まあ「文字」に拘るかどうかはプロジェクトの特性にもよるだろうが、
実際今までの開発にあたってそこまで「文字」の存在を重要視してきたことはそこまで多くないのである。
そういう前提で臨んだとき、
UTF-8だと「全角文字で4バイトになる」というのは全角文字としては「異質」であり、(別に符号化のルール上当前であって異質でもなんでもないが)
そのうえ必要性がそこまででもないとわかるとどうしても敬遠しがちになる。
ただ、第3水準・第4水準の文字の一部が入ってることもあり、
少なくとも日本語的には完全無視するのもいかがなものかという気もする(最近してきた、というのが正確な言い方かなw)。
まあ扱う上での考慮事項やそれに伴う開発の体力等との兼ね合いもあるんだろうが、
もう少し現場が理解を広めていってもいいかもしれないなあ~と、感じたのであった。
(もちろん自分自身も理解を深めなければなるまい)