【GCP】【ひなっち】ひなっちのおはっちを収集するサイトを作った件
題名の通り。
まだ残課題はあるが、基本的に運用フェーズに入ったので、一旦ここらで開発経緯等についてまとめておこうと思う。
ちなみにサイトはこちら↓です
https://hot.rmblankslash.net
はじめに
事の発端はもう結構前で、昔暇つぶしでTwitter4Jを使ってひなっちのおはっちを検索してみたことがあって、それの後継というか完全版(?)。
ひなっちが日々する「おはっち」と、「おはっちリプ」の情報などを収集してみるのは面白そうだよな、という個人的な好奇心と技術的な探求心とひなっちへのファン愛が混ざったミックス趣味。
当時は直近1週間分くらいを個別に収集するので終わっていたが、今回はそれを、日々発生するおはっちを自動で収集して運用できる形でサイトとしてまとめた。
サービスアーキテクチャ
こんな感じ。
まあひなっちのこと知ってる人からすると今さら説明するまでもないことかもしれないが。
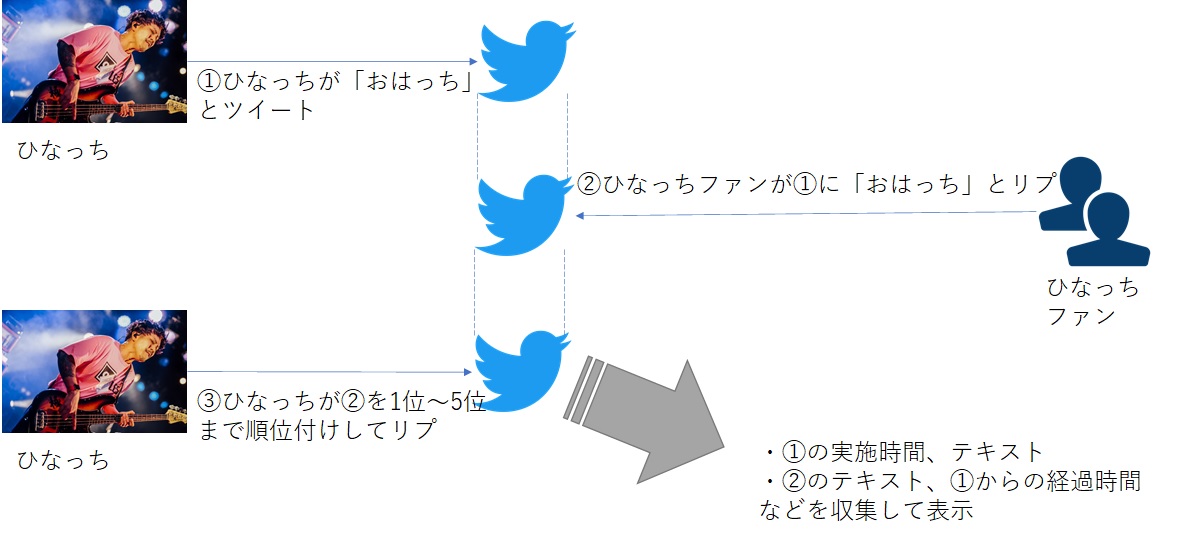
日々のひなっちのおはっちツイートに対し、各ファンが「おはっち」とリプする。
ひなっちはそれを受けて、リプが早かった順に「1番(~5番)」を決めて、対象者に対して改めてリプする。(=以後これを便宜上「n番おはっち認定リプ」と呼ぶ)
これが日々繰り返されている。
で、これを収集してデータとして蓄積してサイトで表示している、という流れ。
システムアーキテクチャ
Architecture Overview
基本はGCP上で構築した(自分のGCPの勉強を兼ねて)。
すごいざっくりした絵で言うとこんな感じ。

リソース別紹介
各リソースごとにちょっと掘り下げてみると、以下のような感じ。
- (A)Twitter(ひなっち)
我らがベースヒーロー、ひなっちのTwitterカウントから発せられるツイート群。
全ての処理の発端。 - (B)IFTTT
If側に[If New tweet by specific user]で(A)を指定し、Then側に[Webhook]で(C)を指定したIFTTTアプリケーション。
ひなっちのツイートをポーリングして後続処理を起動するための仲介役。 - (C)Cloud Functions
ひなっちのツイートを受けて、(D)の作成や(E)の投稿を行う。
(B)は、ひなっちのツイートは「おはっち」ツイートに限らず全部ポーリングして流してくるので、この処理内で「おはっちツイート」か「おはっち認定リプ」だけを処理するよう切り分ける。
実装言語はNode.jsで、内部的にTwitter APIやSlack Incoming webhookを使用(Slackは私宛の通知のためで、完全個人用) - (D)Cloud Firestore
処理結果を蓄積しているデータベース。 - (E)Twitter(俺)
俺のTwitterアカウント。
完全個人用のアカウントだが、このシステムとの関わりという点では、(C)の処理結果を通知先(「ひなっちのおはっちが更新された」旨のツイートの投稿先)として存在する。 - (F)Fiebase Hosting&Functions
WebアプリケーションのHosting環境。
一応Functionsも付いているが、Next.jsのアプリを動かすために使用しているだけにすぎない。Hostingがメイン。 - (G)Github
(C)と(F)のコードを乗っけてるリポジトリ。ただしどちらもprivateなので一般には見れない。
Github Actionsを使いたかったので使ったという理由が大きい。
mainブランチにpushすると、自動で(C)と(F)までdeployが行われるようになっている。 - (H)一般ユーザー
多分多くはひなっちのファンの方だと思うが。
動線的には(E)で「ひなっちのおはっちが更新されました」ツイートから入ってくるのが多いのかな? - (I)俺
ローカルではVS Code + Remote Containerで開発。開発終わったらGithubにPushする。上述した通りdeployはGithub Actionsで自動で行われる。DevOpsだ!
あとはたまに(F)のアクセスログ見たりとか。
ちなみに(C)や(F)で異常が発生する(落ちる)と俺にメールが来る(StackDriver経由)
ポイント
いくつかポイントなどを。
「1(~5)番おはっちが誰か」の判定を、ひなっち自身に委ねていること。
最初は、ひなっちのツイートを定期的に監視して、ついてるリプをtimestampの早い順にソートして、自前で「1番おはっちが誰か」を探ろうと考えていたが、以下理由により採用を身送った。- 実装がガリガリしそうで面倒くさい。結構大変なロジック書くことになりそうだし、テストの仕方もよくわからん
- ひなっちのおはっちの定期監視にあたっては、Twitter APIを叩くことになるが、実行間隔によってはRate Limitに払拭する可能性があり、あまりやりたくない
- そもそも、俺が決めた独自のロジックで「1番が誰か」とかを決めていいのか?ひなっち本人が認定することのほうが大事なのではないか?と思った
3.が割合的には一番大きいかな。(言い分はかなり言い訳っぽいけどw)
ただ実際、自前で判定を行わず、ひなっちに認定を任せることで、システム構成は非常にシンプルになったと思う。- 特にひなっちの「おはっち認定リプ」に関しては、認定するタイミングで一気に投稿されるので、IFTTT側のポーリングで複数ツイートが連携されるケースが想定された。
このため(C)で(D)を作る際にトランザクション処理を採用している。
これは自分用のテストアカウントを使って何度か実験し、ほぼ同タイミングでfunctionが呼ばれた場合でも競合することなくデータ更新できることを確認した。 - 最初期の構想では、IFTTT経由でツイートの本文や投稿日時等、処理に必要な情報を全部貰う想定でいたが、色々あってこの方式はやめた。
その辺の苦労話はQiitaにまとめたので、まあ興味があれば。
これにより(C)で自前でTwitter APIを実行する必要が出るなど、(C)の処理が膨らんでしまったが、まあこっちのほうが自由度があがったので結果オーライと今は思っている。 - Twitter APIはV1.1とV2.0を両方使っている。
というのも、V2.0には現時点(2021年4月時点)ではツイートのPOST機能がどうやら存在しないようだからである。(ツイートの投稿はV1.1のAPIに頼らざるを得ない)
これは今後の拡張に期待したい。 - 月別のログを表示する画面では、React Selectというモジュールを使って月の選択を可能にさせている。
これ最初は使い方がわからなくて、色々調べて実現できたので、個人的には思い入れのある機能のひとつである(大したことやってないがw)
このページが非常に参考になった。
個人的に、Reactを飛ばしていきなりNext.jsに入ったので、Reactに関しては知識が薄いのが正直なところで(Next.jsもそんなに大層な知識があるわけではないが)ちょっと凝ったのを作ろうとするとこういうボロがすぐ露呈する。 - (C)のGithub Actionsでは、Google CloudのGithub Actions marketplaceで提供されているものを使っている。
これ、Service AccountをGithubリポジトリのsecretsにいれろってのが最初よくわからなくて、とりあえず秘密鍵だけ設定していたんだが、全然違った。
Service AcccountのJSONファイルの内容をそのままべたっと貼りつければいいんだねこれ。
残課題
現時点で抱えている残課題。
- ひなっちのScreen Name="Hinatch"をIFTTT上に固定で指定している。よって、ひなっちが気まぐれでScreen Nameを変えると、後続処理が動かなくなる。
- IFTTTというよりScreen Nameを変更できるTwitterの仕様に依存してるので、これ自体はどうしようもない。IFTTTがScreen NameベースじゃなくユーザーIDベースでやってくれるならこの限りではないが。
Cloud Functions+Pub/SubでCronjob的な自前のポーリング処理(Screen NameではなくユーザーIDを使うやつ)作れば可能だが、Twitter APIのRate Limitを気にする必要もあり、あまり多頻度に動かせないし、そもそも面倒くさい(これが本音)。
結果、現実解が見つかってない課題。
- IFTTTというよりScreen Nameを変更できるTwitterの仕様に依存してるので、これ自体はどうしようもない。IFTTTがScreen NameベースじゃなくユーザーIDベースでやってくれるならこの限りではないが。
- Firestoreのデータの保持期限を決めていない。なのでこのままだと延々貯まり続ける。
- 個別に定期削除処理を作るしかなさそう。DynamoDBのTTL機能みたいのあればいいのに。
ただ基本的にデータ量少ないので、定期削除を用意するにしても、しばらくは放置して問題なさそう。(そこまで急ぎではない)サービス仕様としてどうするかの兼ね合いもある。
あとは、このまま増加を続けた場合の費用がどの程度になるのか確認も必要。というか、ある意味それが「保持期間」の決定打になると思われる。
- 個別に定期削除処理を作るしかなさそう。DynamoDBのTTL機能みたいのあればいいのに。
- 例えばFirestoreのバックアップや、HostingしているWebアプリの可用性等、非機能要件がない(はっきりしていない)。
- こんな個人の趣味サービスに高い非機能要件はそもそも求めてないので、原則、使用しているマネージドサービスの仕様に頼るだけで、個人的には良いと思っているが、そもそもSLAとかどんなだっけというのを把握していないのはヤバイよなぁとは薄々感じている(でも特に何か行動を起こしていない)
なおFirestoreのバックアップだけはちょっと個別に考えてみても良いかもしれないな、とは思っている。
- こんな個人の趣味サービスに高い非機能要件はそもそも求めてないので、原則、使用しているマネージドサービスの仕様に頼るだけで、個人的には良いと思っているが、そもそもSLAとかどんなだっけというのを把握していないのはヤバイよなぁとは薄々感じている(でも特に何か行動を起こしていない)
- デザインが全般的にイケてない。もともと凝るつもりはなかったのだが(そもそも凝れるだけのスキルがない)それにしたってイケてない。
- これは根本的にスキル不足に起因するので、残念ながらすぐにどうこうできるものでもない。デザイン部分に特化して継続的にキャッチアップを図っていくしかない。
- Firebaseのキャッシュ制御に柔軟性がない(任意のタイミングでこちらから全キャッシュを削除するような措置がとれない)
- このサービスは、「ひなっちがおはっちしたとき」と「ひなっちがおはっち認定リプをしたとき」にだけデータが更新されるので、極論そのタイミング以外は誰か人柱にキャッシュしてもらった後は放置で構わないはず。
この2回のタイミングで、AWSでいうCloudFrontに対するInvalidationの作成が指示(つまりその時点のFirebaseキャッシュを全部クリア)できると、とても良かったのだが、どうも探してる限りではそういうのはFirebaseには存在しないらしい。
一応こういうのは見つけたので試してみたが、どうも想定通りに動作しているようには見えなかった。まあそもそも出自がStackOverflowだしな…
この辺はマネージドサービスを使用しているが故の弊害というか…痒いところに手が届かない問題。
ちょっと調べた感じでは、Cloud CDN使えば出来そうだなーと思ったが、最早後の祭りなので、一旦このまま運用としては継続させていただく。
- このサービスは、「ひなっちがおはっちしたとき」と「ひなっちがおはっち認定リプをしたとき」にだけデータが更新されるので、極論そのタイミング以外は誰か人柱にキャッシュしてもらった後は放置で構わないはず。
- テストコードが充実していない。
- というかなんなら(F)の方は用意すらしていない。
(C)には一応あるのだが、凄い簡素な単体テストのコードが数個あるだけだし、もうずいぶん前にテスト済で初期から改修もしていないので、現状ただの流れ作業に過ぎない(あってもなくても変わらないレベル)
基本Jestを使うのだが(というかJest以外知らない)、簡単な単体ロジックならともかく、APIをどのようにテストするのかの知見がなく、深堀する前にここまで来てしまっている。
ただ、これは他の課題に比べて、ちょっと気合入れればある程度先には進みそうなので、どこかで時間つくってやってみたい。
個人的にはJest以外にSeleniumも使ってみたくて、その辺の良い実験台になれればいいなあと薄っすらボンヤリ考えているところである。
- というかなんなら(F)の方は用意すらしていない。
あと細かいところではちょいちょいあるのだが、いずれも急ぎではないので、追々整えていこうと思う。
おわりに
もともとデータ的に興味のあった「ひなっちのおはっち」を、自分の勉強と絡める形で関わることができたのは、一石二鳥というか、良い経験になった。
特にGCP/Firebase、Github Actionsを使った開発が体験できたのは良かったと思う。細かいところも含めて色々学びがあった。
「システム開発」の素材としては、規模的・利用範囲等の面で丁度良いと思うので、これを使って色々勉強出来たらなあと思っている次第である。
余談
IDの「hot」というのはHinatch Ohatch Trackingの頭文字をとったものだが、後になって「Tracking」(追跡)は何か違うなと思い、サイト名の付け方間違えたなと今後悔しているところである。
「追跡」というと何かニュアンスが違う気がするな…という感覚なのだ。
むしろその後自分なりに使いだした「収集」(Collect)という言葉の方が個人的にしっくり来ており、だったら最初からhoc(Hinatch Ohatch Collection)にしておけば良かったなと思っていたりする。
まあ今となっては後の祭りだが…