Remixで英単語フラッシュカード機能を実装した話
Remixで英単語フラッシュカード機能を実装したので、その話をする。この機能は「オレ専用の社内(?)管理サイト」に実装しており、この話の詳細はこちらの記事で語ってるので興味があればそちらを参照いただきたい。
はじめに
冒頭の記事でも書いたように、「オレ専用の社内(?)管理サイト」には、俺が行う様々な日常の作業の実施補助・記録管理するための機能を順次追加実装していく予定で、それで最初にまず「Tシャツの記録」機能を作ったわけだが、それとは別にもともと想定していたものとしていて「英単語の復習」機能を実装したいと思っていて、それを今回実装したという話である。「Tシャツの記録」とは全然性質が違うのだが、「日々実施すること」という意味では同じ位置づけなので、同じアプリに乗っけたほうがわかりやすいという発想による。
機能性
英単語の入力・更新・検索機能
フラッシュカードに入力する英単語を入力・更新・検索する機能。言ってしまえばマスメンである。そういってしまえば単純な機能だが、いくつかポイントがある。
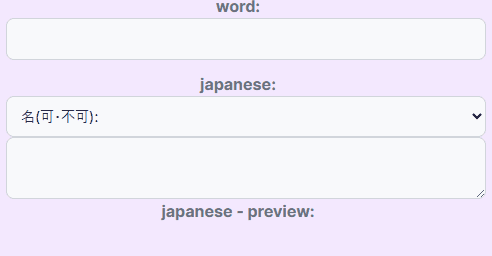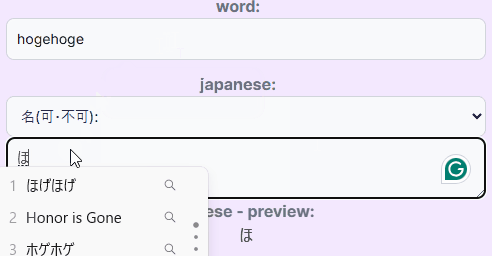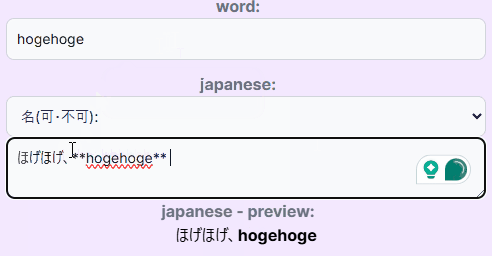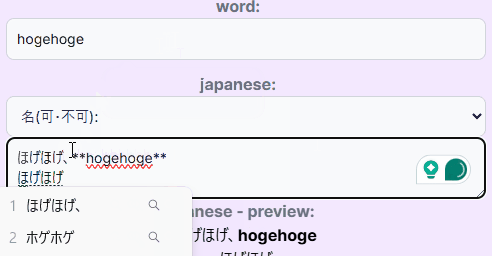
- 対訳(日本語訳)を入力する項目にマークダウンを許容した。特にほしかったのは 「強調」 の表現で、これだけできればマークダウンに拘る必要もなかったのだが、マークダウン全般許容しちゃったほうが手っ取り早いなと思ってそのままOKとした。これは物理フラッシュカードでも時々意図的に使っていた表現で、例えば"leisurely"は見た目が副詞っぽいが実は形容詞で、「形容詞」の部分に下線引いたりして強調表記していた。こういう表現をシステム側でも実現したかった。入力は普通にマークダウンで書いて、表示側で
react-markdownを使って入力されたマークダウンをレンダリングする。マークダウン表記があるかどうかを入力段階で判定し(onChangeイベントとuseState使って動的に…)、DBに保持。マークダウン表記がないものはそのまま表示する(が、改行だけ<br/>にするとかちょっとした見た目の調整はしている)。 - 「どこで知ったか」(どのような使われ方をしていたか)を入力できる任意の入力項目を用意した。辞書上の意味と実際の使われ方で微妙にニュアンスが異なる or もはや全然違う使い方している、というケースはままあるので、それを記録しておきたいという意図による。物理フラッシュカードのときにはこれはスペースの関係上どうしても記録しきれず、自分の脳に収めるに留まったのだが(印象に残ってる単語の「使われ方」は今でも覚えてるが数は少ない)、今後勉強をしていくなかでこの情報を記録しないのはもったいないし、そのとき見ていたページのURLとかコピペするだけでよいので、そんな手間かかるものではないので。
入力のイメージ
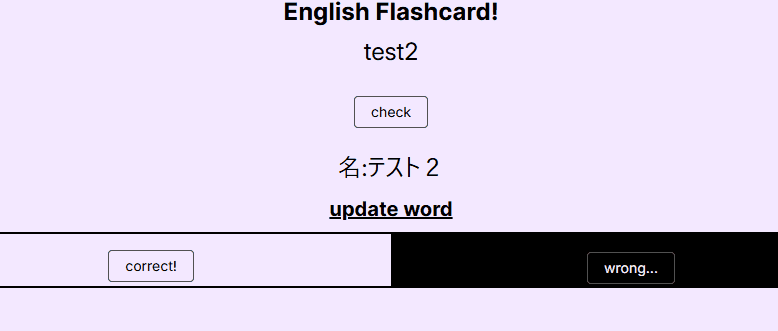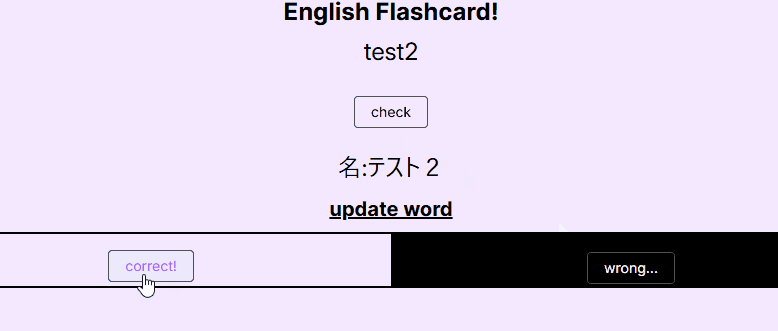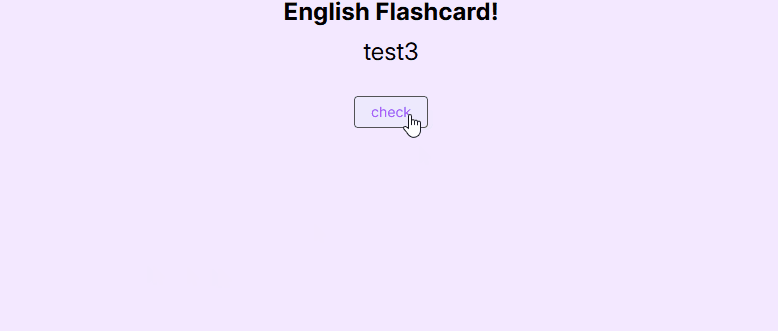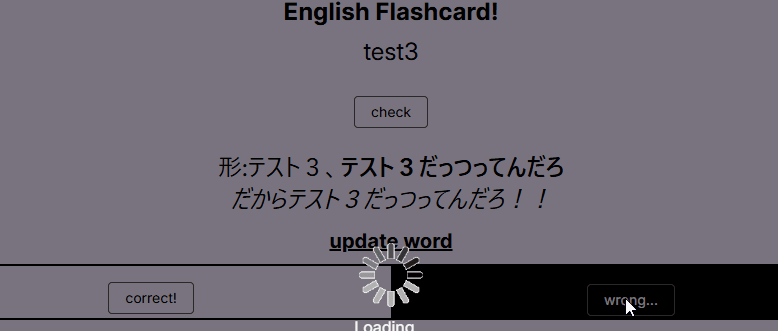
フラッシュカードの実施機能
上で入力した単語の中から1つを選び、英語 or 日本語の方の意味だけを画面表示させて、チェックボタンを押すと対訳側の意味が表示され、合ってたボタン or 間違ったボタンを押す。単純にそれを繰り返すだけのシンプルな1画面である。loader()で出題する単語を取り出し、action()で正否の記録を行った後、redirectでまた自画面に戻ってきて再度loader()が実行される。その繰り返し。この機能には「モード」があり、「英語に対して日本語の意味をあてる」のと「日本語に対して英語の意味をあてる」2種類がある。モードはパスパラメータで指定されるが、上記の基本機能自体はモードによって変化しない(出題される項目と対訳側の項目がかわるだけ)。物理フラッシュカードで実施していたのとほぼ同じ運用ができるよう再現した。ポイントは以下のあたり。
- 出題する単語を選ぶ際、「まだ一度も出題されていない単語」「出題されたことはあるが間違えた回数が多い単語」「最後に学習してからの経過日時が長い単語」などでソートして、さらに取得した結果からランダムに1つ選ぶという処理を仕組んでいる。これにより、まだ学習していない単語・苦手な単語など、優先的に学習するべき単語が選択されやすくなっている(はず)。このテのアルゴリズムでは、昨今よく「忘却曲線」が採用されていると聞くが、これに該当するような立派な仕組みではないが(そもそも「忘却曲線」のことを良く知らないが)、まあ今のところはそこそこ想定通りに動作しているのでOKとしている。物理フラッシュカードでは、フラッシュカード内ならともかく、フラッシュカードをまたいで適当に(ランダムに)単語を一つ選ぶ、というのがどうしても難しかったので、そこの運用課題をクリアしたものである。ただこの仕組みには課題も感じており、そこは後述する。
- 対訳側の意味を表示するとき、いわゆる「フラッシュカードをめくる」行為は、内部的には非常に単純で、
useStateで定義した開閉状態のboolean変数(初期値false=表側を表示している状態)を、ボタンクリックにより逆転させて(=trueにして、つまりフラッシュカードをめくって裏面を表示する)、false時には隠していたdivタグを開くという、いわゆるtoggleの開閉機構を採用している。これは自作漫画サイトRESIGN THREATの音楽ページで実装しているものをそのまま流用した。なお、Remixでは、useStateで変更した状態は、リロードしない限り維持される(とChatGPTにきいた)ので、このままだと、ある特定の問題のときに「開いた」状態が、次の問題でも同様に「開いた」まま初期表示されてしまう。このため、action()処理内で、useNavigationを使ってnavigation.state === "idle"で処理の完了を判定し、この状態をリセットするよう実装した。ちょっとした修正だったが、useNavigationなんて便利なものがRemixにはあったのかと知れたのは良い体験だった。 - 英単語のマスタには、「出題された回数」「正解した回数」「最後に出題された日」を項目として保持しており、これらが上記の「出題する英単語を選定するロジック」で使用される。ページ遷移するたびにこれらの情報を更新して、次の出題に備える。フラッシュカードの勉強記録そのものは別のトランデータとして管理し、こちらには「学習の開始」「学習の終了」項目を保持して、ページ遷移するたびに「学習の終了」の方の時間を毎回上書きしていき、その日の学習時間を集計できるようにする。集計した学習記録はスタディサプリにその日の勉強時間として入力する。ただこの仕組みは、手っ取り早く予見を実現するために採用したアーキテクチャで、課題も感じている。これは後述する。
実施のイメージ
フラッシュカード機能の課題
- 単純に移行が完了していない。ので、完全な形でフラッシュカードの勉強するのにはまだ不足がある。物理フラッシュカードは手元に22~23個あるんだが、1つのフラッシュカードに大体80枚あるので、単純計算で1840個の英単語を、↑の英単語の入力機能でせっせと手入力していかないといけない。これは前のTシャツのときと比べてCSVなんかのデジタルデータにはなってないので、本当に地道に画面に1つ1つ手入力しなければならない。この機能を作った時からこの手作業移行は覚悟はしていたが、思った以上に手間がかかる。完全に移行し終わるまではまだだいぶ先になりそうである。
- 英単語を選定する際の要件のうち、「まだ学習していない単語」「最後に出題されてからの経過日数が長い単語」「間違えが多い単語」は、それぞれ性質が違うんじゃないか?というのを薄っすら感じているのだが、具体的にいうと前者2つと後者1つが性質的に異なるもののように感じるのだが、それを機能に反映できるほど整理できていない。今のロジックだと、この3つの条件でソートした上位何件かを
limitで取得したうえで、さらにそこに「その中からランダムに1つ」という選び方で出題する単語を決めているので、前者2つか後者1つか、どちらに該当する単語が選ばれるのかがわからない。最悪前者2つだけの問題が連続したりするケースも考えられる。単語が多くなればなるほど、勉強期間が長くなればなるほどその傾向は顕著になりそうな気がする。前者(or 後者)に該当する単語だけを集中的に出題し続けるモードとか、そういう風に分別したほうがいいのか?とか、「そもそも『ランダムに1件取得』っているのか?」とか、その辺の有象無象のアイディアが色々モヤモヤと脳内を駆け巡っている状態で、どのようにするのが「俺の」学習目的に対して最も有効か、というのが整理できていない。今の所はそれほど変な出題のされ方はないので気になってないが、長期的に見てどうなるのかがわかっておらず、頭の片隅に置いてある。 - 英単語の選定がページ遷移のたびに起きるので、その分DBアクセスが生じる。この場合のbandwidthって大丈夫なんだっけ、という一抹の不安がある、というよりあまり詳しく調べられていない。Supabaseのstorageには月5GBまでというbandwidthの制限があるようなのだが、storage起点の話しか語られておらず、DBがこれに該当するのか不明だし、この処理構成で実質どの程度消費するのかも、まだ正確に把握できていない。仮にこの運用でbandwidthの制限に迫るような状態になるなら、出題する単語を最初に一括で持ってきて、出題はその中で行う等の機能変更が必要になる。
- この機能は、最後に出題された日時、出題された回数などを記録するために、頻繁にDBへの更新(UPDATE)が入るのだが、Postgresqlの特性上、あまりにも大量にUPDATEしまくると、そのうち肥大化(bloat)して、パフォーマンスに大きな影響を与える可能性が懸念される。俺しか使わないのでそれほど懸念するほどでもないかもしれないが、長期的にはどうなるのか不透明。「気づいたときにはselectがまともに返ってきません」という事態になるのは避けたい。そもそもそういえばSupabaseってAutovacuumしてるのか?ってのが調べられていない。この辺の記事(参考1、参考2)読むとなんかAutovacuumしてない気がする。まあでも完全個人用のアプリなので、手動で
VACUUM FULLかけるのは別に全然問題はない(なんの調整も不要で自由にブン投げられる)。最悪それで乗り切るか…くらいの呑気な考えでいる。
フラッシュカード機能でやってみたいこと
出題された問題に対して、「合ってたか」「間違ってたか」は、基本的には自己申告である。なので「実は間違ってたけど合ってたことにしちゃお!」みたいな行為がまかり通ってしまう。俺しか使わないんだし、そもそもフラッシュカードって本来そういうものだから別に気にしなくていいんじゃないの、という感じもするが、これをある程度厳密化できないか、というのを考えている。
「出題された英単語に対して対訳の意味を入力させて、サーバー側で正否を判定する」というのを実装すれば良さそうだが、上で書いたとおりで、日本語側の意味を入力する項目に、「品詞の情報」や「受け身不可」などのメタデータまで含めて入力している関係上、完全一致で正否判定するのは実質不可能である。日本語->英語モードならそれでもある程度なんとかなりそうだが、「同じ意味を持つ別の英単語」があるので(coworkerとcolleagueとか)、それも期待通りに動作するか怪しい。じゃあ「部分一致にして一致したレコードが1件以上あれば『合ってる』とみなす」とかにすればいいんじゃないか?と考えたが、例えば「開始する」という意味を持つ単語に対して、「はじめる」と入力された場合、それは「間違ってる」のか?と自問すると、個人的には疑問符が付く。そうなると、例えばMecabとかの形態素解析を使うとか、あるいはOpenAIのAPIなど、AIを使って判定させるとか、そういう話になってくる。この辺までは薄っすら考え付いたのだが、そこまでして開発したい機能か?これ??という気持ちになってきて、いまいち乗り気にはなっていない。それにそもそも、正否を確認するまでに、「ユーザーの入力を必要とする」という待ちのステップが1つ加わるので、学習の効率は確実に落ちる。本来のフラッシュカードを使った勉強のイメージともかけ離れている。その運用性を損なってまで作るべき機能という気は、(俺しか使わないという前提を抜きにしても)個人的には感じない。
それをやるくらいなら、「選択肢を作って選ばせる」のほうがまだ現実的だと感じる。つまり、英単語の選定に加えて、正答1つ+誤答3つくらいを選定して表示させ、クリック(スマホだとタップ)させて正否判定するのだ。スタディサプリ等のアプリでも同じような機能性は備わっており、実装も(上記に比べれば)そこまで難しくなく、現実的である。一方、そもそも「間違ってる選択肢」をどう選定するか?というのが課題として残る。単純に乱数で選定するのは全然難しくないが、それだと問題が簡単になりすぎる(一目瞭然になる)気がする。例えば"obscure"の正しい意味は?という問題に対して選択肢が「1.スイカ (watermelon)」「2. レモン (lemon)」「3. 有耶無耶にする (obscureのこと;正答)」「4. りんご (apple)」と出題された場合、3.以外の他の3つが正答と比べてかけ離れすぎているので、問題にならないのでは?という懸念がある。これはあくまで例で、watermelonもlemonもappleもわざわざ登録なんぞしてないし、他の単語にしたって、これほどはっきり意味が違う単語が偶然3つ選ばれるという可能性もそこまで高くないとは思われるが、しかし「正答の意味」をまるっきり無視して、「他の単語から無作為に誤答用に3つ抽出」だと、あまりにも芸がないというか、そんなことして抽出して問題にすることになんか意味あるの??という気はしないでもない。なので、例えば少なくとも最低1つは「元の単語と近い意味を持つ単語」を選ぶ、等して、「問題」感を出したい。が、そのやり方がピンと来ていない。それこそMecabとかOpenAIのAPI使えばいけそうではあるが、選定のたびに毎回そこまでするとオーバーヘッドがかさみそうだし、完全自分用のprivateなアプリでそこまでするのもなぁ…という状態。そういうわけでこの案に関しても現状重い腰が上がらないでいる。ただ実装的には興味もあるので、(いったん上記の懸念は抜きにして)これはそのうち作るかもしれない。やってみないと課題になるかどうかもわからないしな。まあ「作ってみたい」によるところが大きいのだが。
というわけで現時点では機能化する予定はないのだが(他にやりたいことがあり、そっちを優先させたい)、これはそのうち別の形で実装するかもしれない。
余談
身もふたもないことだが、こんなのわざわざ自作しなくても既に既存でそういうアプリあるんじゃないかというのはごもっともである。単純に技術者的好奇心が先行していてそういう発想がなかったというのが本音で、気づいたときにはもう作ってしまっていた、というところだ。後で探してみたらQuizletというアプリというのが今回作ったのとほぼ同じ位置づけで使用できるということはわかった。わざわざ自分で作らなくても、こっち使えば良かったなというのは、今更ながら少し思っている部分はある。(後悔はしてないが)
Quizletは、ちょっと触ってみたんだが、英単語を入力すると自動で候補ワードをsuggestし、対訳部分も自動翻訳で埋めてくれるし、気に入らなければ自分で書き足す or 書き直すことも可能で、入力の補助機構は優れていると感じた。無料でも単純なフラッシュカード機能は使えるし、一般的な利用用途であればこれで十分なんじゃないだろうか。
気になったところとしては、、、
- 対訳側(日本語の意味)の入力項目が、極論いうとただのテキストボックスなので、例えば複数の品詞を持つ単語で「可算名詞」「自動詞」とかの品詞の情報を分けて入力したり、「進行形不可」「通例受け身で」「通例複数形で」「後ろに名詞(動名詞)をとる」などの関連するメタデータを補完しようとすると、この入力項目では無理が出てくる。物理フラッシュカードを利用していたころの学習ではこういう使い方していたので、この入力項目だと運用に難ありだった。
- (まあ当然だと思うけど)入力時にマークダウンをいれてテキスト装飾する機能は備わっていない。基本的に太字しか使わないんだけどそれでも稀に使用したかったので、Quizletだと入力機能が足りない。
- 英語→日本語方向のフラッシュカードしか提供されていない。あまりやらないが、たまに逆方向-日本語→英語のフラッシュカードもやってたので、そっちもできるようにしたかった。
- 検索機能が(おそらく)存在しない。英単語で検索したり、逆に日本語訳で検索したりできない。英単語ベースで同じものが登録できないようにはなってるが、逆に言えば検索できるのはここの部分だけの超限定的な機能である。
- 無料版だと(特にブラウザで)有料版へのアップグレード広告が結構な多頻度で出てきて、単純にちょっとうざい。
まあこういう「他人が作ったアプリ」で100%満足のいくものって存在しないのは世の常で、「文句あるなら自分で作れ」って話であり、実際少なくとも俺にはその能力があるのだから、自分で作って結果オーライだったなと思うようにしている。
おわりに
実装したものはシンプルな機能だが、(これに限ったことではないのだが)実際に開発してみると色々と考えること・考えさせられることもあり、なかなか奥深い、楽しい開発体験だった。まだ細部は改修が必要な部分はあるので、その辺を継続して実施し、まとまったところでまたブログにしたい。