【Drizzle】はじめました
Drizzleを使い始めてみたので、その振り返りをしてみる。個人的に使い慣れてるORMであるPrismaとの比較、Remixアプリ、Cloudflare Workersへの導入の記録など。
Getting Started
動作確認用の超小規模テストプロジェクトをまず作った。基本的には以下のページの手順に従って実施。
https://orm.drizzle.team/docs/get-started/postgresql-new
- Prismaでいうところの
prisma/schema.prismaにあたる定義ファイルはDrizzleの場合drizzle.config.tsとschema.tsの2つになる。テーブル定義はschema.tsに書いて、DB接続部分はdrizzle.config.tsに書く。 - Prismaの場合、スキーマは接続文字列の末尾に
?schema=hogehogeのように指定するが、Drizzleの場合はschema.tsで個別に指定する。好みの問題かもしれないが個人的にはDrizzleの方が分かりやすくて良い。import {pgSchema} from 'drizzle-orm/pg-core' export const schema = pgSchema("hogehoge"); - テーブル定義はZODみたいな感じで書く。
- 個人的にはテーブルの主キーにUUIDv4の自動採番を使うことが多いのだが、これは以下のように書く。
import {uuid} from 'drizzle-orm/pg-core' const id = uuid('id').defaultRandom().primaryKey(); - 共通カラムなど、使いまわしができるものは個別定義しておいたほうがわかりやすい、というこちらの記事は非常に参考になった。
- スキーマ
hogehogeにテーブルhugahugaを作る一例import {integer, pgTable, varchar , uuid, timestamp, boolean , pgSchema} from 'drizzle-orm/pg-core'; export const schema = pgSchema("hogehoge"); const id = uuid('id').defaultRandom().primaryKey(); const createdAt = timestamp('created_at', { withTimezone: true }) .defaultNow() .notNull(); const createdBy = varchar('created_by' , {length: 255}).notNull(); const updatedAt = timestamp('updated_at', { withTimezone: true }) .defaultNow() .notNull(); const updatedBy = varchar('updated_by' , {length: 255}).notNull(); const isDeleted = boolean('is_deleted').notNull().default(false); export const hugahugaTable = schema.table('hugahuga', { id: id, createdAt: createdAt, createdBy: createdBy, updatedAt: updatedAt, updatedBy: updatedBy, isDeleted: isDeleted, name: varchar('name', {length: 100}), amount: integer('amount'), }); - テーブル定義のオブジェクトのプロパティ名は実際のテーブルのカラム名と必ずしも一致しない。テーブルのカラム名は型定義の際に第一引数で指定する文字列になる。例えば上で言うと
createdAtはテーブル定義のオブジェクト上はキャメルケースになっているが、const createdAt = timestamp('created_at', ...と定義しているように、実際のテーブルのカラムはcreated_atとスネークケースになる。
- 個人的にはテーブルの主キーにUUIDv4の自動採番を使うことが多いのだが、これは以下のように書く。
- Step 6 - Applying changes to the databaseの部分で、ドキュメントだと
npx drizzle-kit pushを実行するように書いてあるが、これだと個人的にはうまくいかなかった。というかこれは多分当たり前で、少なくとも最初の真っ新な状態(migrationのファイルが1つもない状態)ではスカになるだけなので、まずは反映させるテーブル定義が必要である。これはnpx drizzle-kit generate、npx drizzle-kit migrateで行う。- ドキュメントみると、
npx drizzle-kit pushは、Primsaでいうnpx prisma migrate deployに近い性質のもののように見えるが、同じことはnpx drizzle-kit migrateでも出来るので、イマイチ違いが分からない。後述するCloudflare Workersのビルドに際してもmigrateのほうを使っており、pushは使用していない。このコマンドいつどういう場面で使うんだろうか?? npx drizzle-kit generateすると./drizzleディレクトリ下(drizzle.config.tsの設定に依存)にSQLが作成される。この際--nameで名前指定しないと作成されるSQLのファイル名はDrizzle側で自動で付与される(Dockerコンテナの名前が自動でつけられるのと同じ感じ)。以下のような感じPrismaは確か(記憶が確かなら)$ ls drizzle 0000_nostalgic_magdalene.sql 0001_friendly_rage.sql meta--nameないとそもそもエラーになったはず(--nameパラメータが実質必須だったはず)なので若干使い勝手が違う。(npx prisma migrate dev --name=hegehegeのように)npx drizzle-kit migrateすると、DBにdrizzleというスキーマが作成される。上の例のようにpgSchemaで個別にスキーマ指定しているならそのスキーマも作成される。以下のような感じ。postgres=# \dn List of schemas Name | Owner --------------+------------------- drizzle | postgres hogehoge | postgres public | pg_database_owner
- ドキュメントみると、
schema.tsでテーブル定義のオブジェクトをexportしておいて、業務処理側でそれをimportしてORMとして使う。INSERTなら以下のようにする:import { drizzle } from 'drizzle-orm/node-postgres'; import { hogehogeTable } from './db/schema'; const db = drizzle(process.env.DATABASE_URL!); const test: typeof hogehogeTable.$inferInsert = { name: 'test ' + new Date().toISOString(), amount: 100, createdBy: 'test', updatedBy: 'test', }; const insertResult = await db.insert(hogehogeTable).values(test).returning();- INSERTの際に指定しているのは
name、amount、createdBy、updatedByの4項目だけで、他の項目は未指定。これでもコンパイルエラーにはならない。これは外の項目はテーブル定義側でデフォルト値の指定があるからである。 returning()を書いておくと挿入したテーブルレコード(の配列)を示すオブジェクトが返却される。この例(hogehogeTable)だと以下:というか逆にいうとconst insertResult: { id: string; name: string | null; createdAt: Date; createdBy: string; updatedAt: Date; updatedBy: string; isDeleted: boolean; amount: number | null; }[]returning()を書かない場合はこの型のオブジェクトを返却してくれない。。(Drizzle固有のなんかの型になるので使いづらい)またこの例のように、単一レコードの挿入でも戻り値が配列になるので、挿入後のレコードのidを取り出したいといった場合はinsertResult[0].idのようにする必要がある。- 生クエリを書く場合(Prismaでいうところの
$queryRaw)はdrizzle-ormに含まれるsqlパッケージを使って以下のように書く:ちょっとしか探してないが、戻り値の型指定ができなかった。Prismaはこの部分をかなり直感的に実装できるので、個人的にはここに関しては(今の所は)Prismaに軍配が上がる。ただ、Drizzleの場合も、戻り値は別に難しい型でもない。import {sql} from 'drizzle-orm'; const result = await db.execute(sql`select to_char(current_timestamp,'YYYY/MM/DD HH24:MI:SS') as ct`);QueryResult<Record<string, unknown>>という型で、この名称とジェネリクスからすでになんとなく内容がわかる。console.logにそのままぶん投げてみたところでは以下の形式の結果が得られた:
実際の結果だけが欲しい場合はResult { command: 'SELECT', rowCount: 1, oid: null, rows: [ { ct: '2025/09/26 10:01:14' } ], fields: [ Field { name: 'ct', tableID: 0, columnID: 0, dataTypeID: 25, dataTypeSize: -1, dataTypeModifier: -1, format: 'text' } ], _parsers: [ [Function: noParse] ], _types: { getTypeParser: [Function: getTypeParser] }, RowCtor: null, rowAsArray: false, _prebuiltEmptyResultObject: { to_char: null } }.rowsを取り出せばそれで事足りると思われる。 - Cloudflare Workersなどのサーバーレス環境で動かす場合、DBコネクションのオブジェクトをリクエストの処理範囲より外に定義していると、1回目は良くても2回目でエラーになる。以下のようなコードはNG:
ちなみに以下のようなエラーが出る:
import {drizzle} from 'drizzle-orm/node-postgres'; import { sql } from 'drizzle-orm'; const db = drizzle(process.env.DATABASE_URL!); // これがダメ export async function getCurrentTimestamp() { try { const result = await db.execute(sql`select to_char(current_timestamp,'YYYY/MM/DD HH24:MI:SS') as ct`); return result.rows; } catch(error) { throw error; } }
Cloudflare Workersでは、DBコネクションをリクエストを超えて使いまわすことができないことが理由である。上のようなコードだと、1回目で生成されたDBコネクションを、2回目でも同様に使いまわそうとして死亡、3回目で再生成して成功、4回目でまた死亡、…という流れで偶数回目が毎回失敗することになる。(参考記事)なので以下のように書き換えなければならない:✘ [ERROR] Uncaught Error: The Workers runtime canceled this request because it detected that your Worker's code had hung and would never generate a response. Refer to: https://developers.cloudflare.com/workers/observability/errors/export async function getCurrentTimestamp() { try { const db = drizzle(process.env.DATABASE_URL!); const result = await db.execute(sql`select to_char(current_timestamp,'YYYY/MM/DD HH24:MI:SS') as ct`); return result.rows; } catch(error) { throw error; } }
- INSERTの際に指定しているのは
Remixアプリへの導入
最終的にCloudflare Workers上で動作させることを想定して、yarn create cloudflare --template=cloudflare/templates/remix-starter-templateでプロジェクトを開始している。その後の細かい微調整はあるが、Drizzle導入部分に関しては基本的には↑と同じである。
yarn add drizzle-orm pg、yarn add -D drizzle-kit @types/pgしてappディレクトリ化にDrizzleのスキーマ定義ファイルを作り(例:app/services/db/schema.ts)- プロジェクトルートに
drizzle.config.tsを作り npx drizzle-kit generate、npx drizzle-kit migrateする
Drizzleの案内だと真っ新なプロジェクトを想定してdotenvやtsxをインストールしているが、個人的にはRemixアプリにおいては基本的に不要なので、上のステップではいれていない。まあ好みで必要なら入れてください。
上記を実施すると(drizzle.config.tsの設定によるが)プロジェクトルートにdrizzleディレクトリが出来上がるので、それもいっしょにGithubに放り込む。
Cloudflare Workersへの導入
以下のようなカスタムビルドスクリプト(custom-build.shと仮称する)を作成:
#!/bin/sh
echo "start custom build"
echo "start yarn build (remix vite:build)"
yarn build
echo "start npx drizzle-kit migrate"
npx drizzle-kit migrate
echo "end custom build"
Cloudflare Workersのビルドの設定画面で、ビルドスクリプトをsh custom-build.shに変更、Cloudflare Workersのビルドの環境変数にDATABASE_URLを指定:
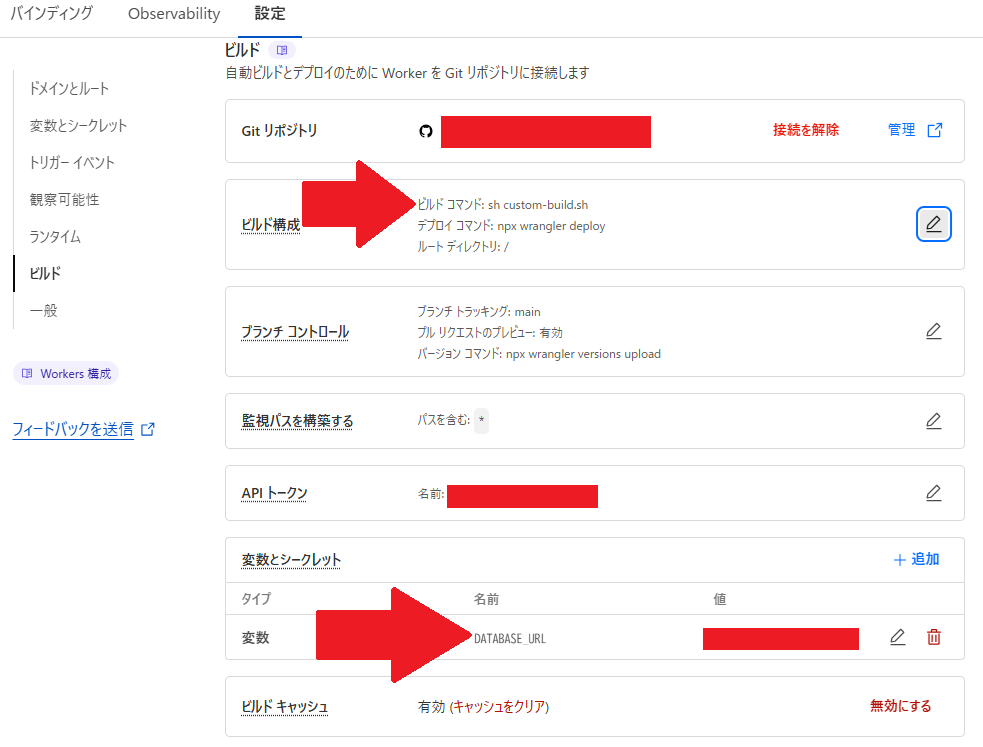
でGithub にpush、deploy!
気になっていたのはプロジェクトのサイズだが(Cloudflare Workersの無料版はプロジェクトのサイズが3MBと決まっている)、ほとんどこの作業の直後の状態でビルドのログに出力されたプロジェクトサイズは
19:30:51.881 Total Upload: 2529.23 KiB / gzip: 438.22 KiB
だったので、まあ全然余裕である。
Prismaの場合、(最近は違うみたいが)Cloudflare Workersの無料版3MBに抑えるために、adapter-pg-workerとかの計量版の専用アダプター使わないといけない等色々面倒なこと考える必要があったのだが、Drizzleはそういうこと考える必要がないのが個人的にとても分かりやすくて良い。もともと、こうしたサーバーレス環境に対応する設計思想で作られている(らしい)ので、実際軽量で、かつ公式にCloudflare Workersへの導入もサポートされていると明言されているのは非常に分かりやすい。Cloudflare Workersで動かすならPrismaより最初からDrizzle使っといた方がよかったような気がする。(個人の意見です)
感想
細かい差異はあるが、実装上はPrismaとほとんど遜色ない使い勝手なので、今の所ほぼ不満がない。より具体的な実装になってくると悩む部分や不満も出てきそうだが、それはPrismaでも同様にあることだし、別にDrizzleに限った話でもない(というかあらゆるライブラリに同様に言える)。
Prismaの場合、Prisma Clientの出力が強制されたあたりから、使い勝手が悪化している節があり(個人の意見です)、Drizzleはその辺一切考えなくて済んでいるのが分かりやすくて良い。それも関連してるが、Cloudflare Workersの動作がサポートされているというのも個人的に心強い。この辺総合しても、今は個人的にDrizzleに軍配が上がっている。最近のPrismaにあまり良い心証をもっていないのが逆に追い風にしてしまっているところもある(公平な目で評価できていない)気がするのでなんとも言えないが。
しばらくDrizzleを使い込んでみようと思います。