タイトルの通り。 これと同じで、なんかこんなことできるかなーと思って試してみたという思いつきチャレンジ系。 なのであまり深い背景や目的はありません。。。
- 前提条件
- DBMS_CLOUD.CREATE_CREDENTIALで認証情報をADWに作成する
- DBMS_CLOUD.SEND_REQUESTを使って試してみる
- DBMS_CLOUD.COPY_DATAを使って取り込んでみる
- S3 Object Put -> Lambda -> ADWの連携をしてみる
- おわりに
前提条件
前回記事とほぼ同じなので割愛
DBMS_CLOUD.CREATE_CREDENTIALで認証情報をADWに作成する
まずはAutonomous Datawarehouse(ADW)のインスタンスを作る。 これはこちらとほぼ同じなので、飛ばして割愛する。
AWSのアクセスキーを作成する
AWSのIAM管理コンソールに移動し、左側のメニューから「アクセス管理」の下の「ユーザー」を選択し、「認証情報」タブを選択。 「アクセスキーの生成」ボタンを押す。
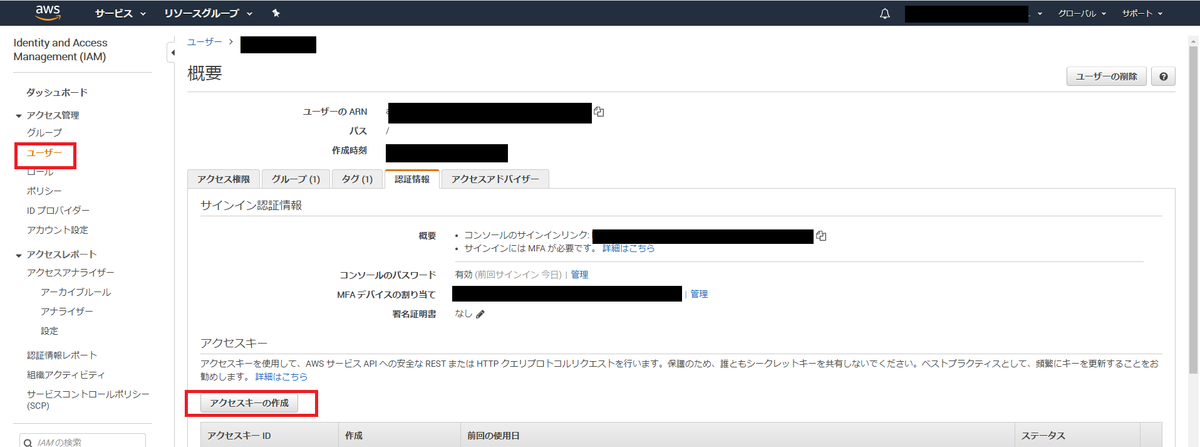
アクセスキーとシークレットアクセスキーが生成されるので、メモる。

Oracle ADWでCredentialを作成する
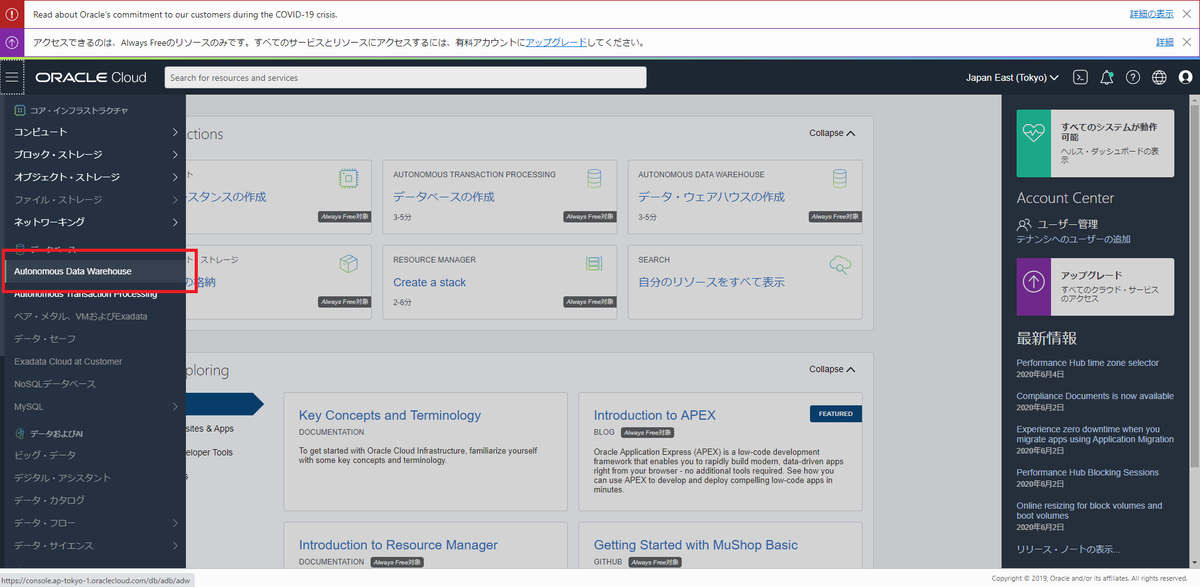
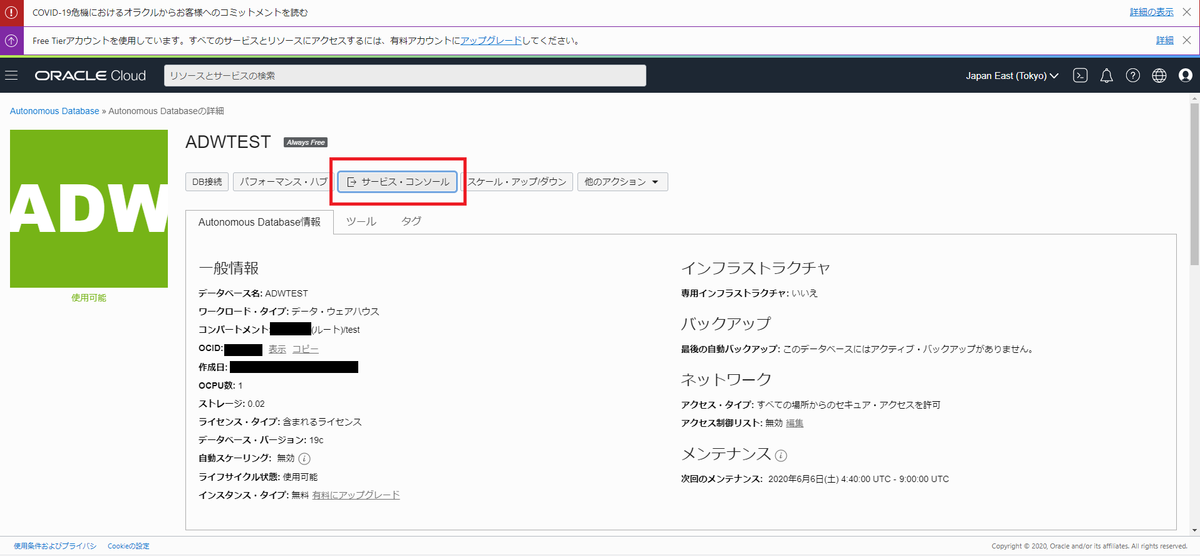
Oracle Cloudに移動する。 ADWの「サービス・コンソール」から「SQL Developer Web」を選択する。
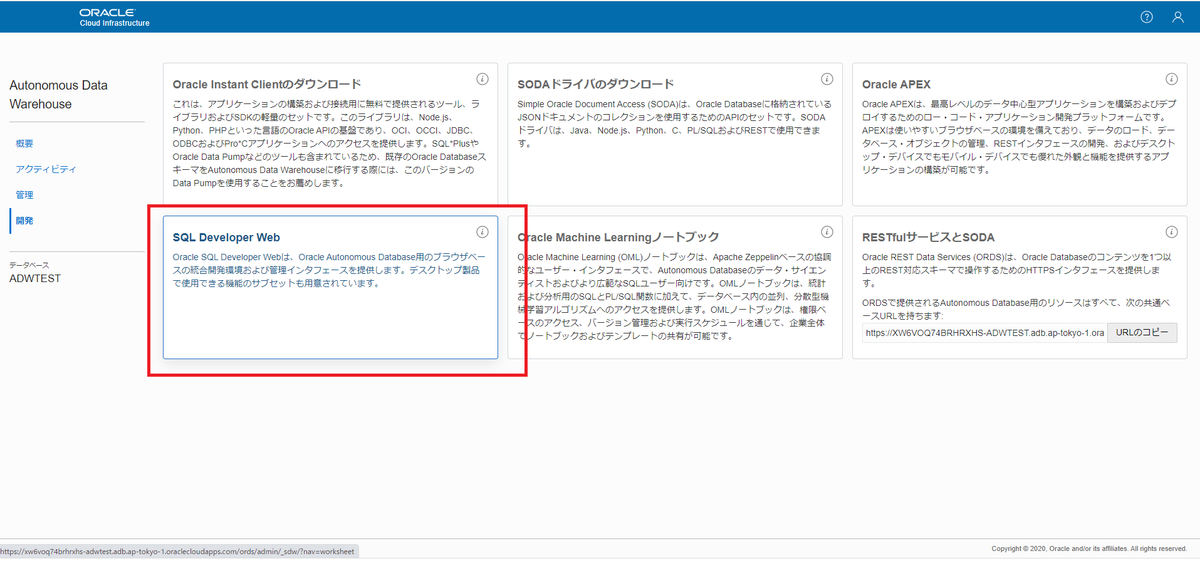
DBMS_CLOUD.CREATE_CREDENTIALを使ってAWSへの認証情報をADW内に作成する。
begin
dbms_cloud.create_credential(
credential_name => 'AWS_CREDENTIAL_NAME',
username => '[AWSのアクセスキーの値]',
password => '[AWSのシークレットアクセスキーの値]'
);
end;
/credential_name=AWS_CREDENTIAL_TESTで作成してみた。

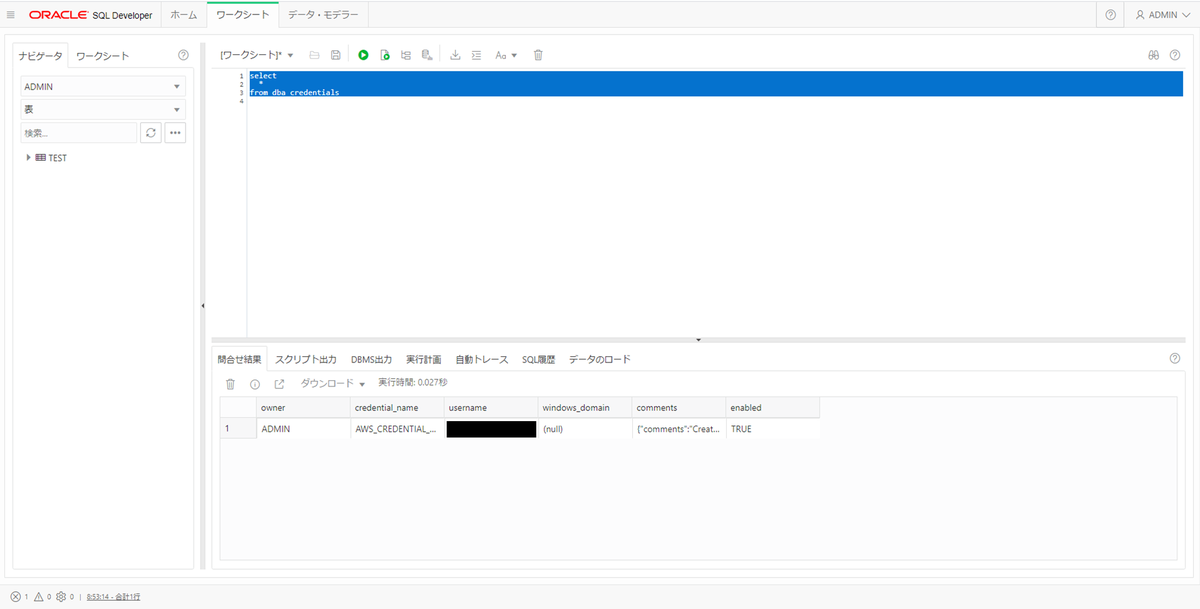
一応、事後確認として、「DBA_CREDENTIALS」をSELECTすると、認証情報が作成されたことを確認できる(詳細は勿論見えない)。
DBMS_CLOUD.SEND_REQUESTを使って試してみる
疎通確認としてS3に適当なファイルをアップロードしたのち、DBMS_CLOUD.SEND_REQUESTを使って試してみる。
S3にテストデータをアップロード
適当なファイルを作ってS3にアップロードする。 とりあえず以下のようなテキストファイルを作る。
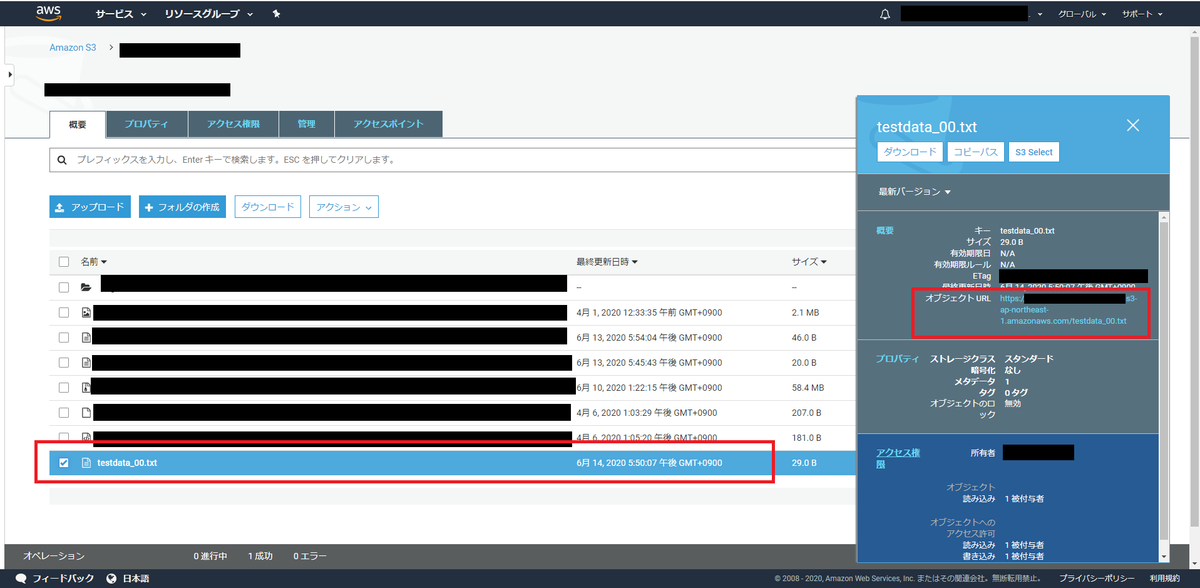
これはテストですtestdata_00.txtとして保存しS3にアップロード。
オブジェクトURLを控える。
まあ、https://[バケット名].s3-[リージョン名].amazonaws.com/testdata_00.txtという形式である。
DBMS_CLOUD.SEND_REQUESTで内容を取得
Oracle ADWのSQL Developer Webに入り、先に作成したCredentialとDBMS_CLOUD.SEND_REQUESTを使って内容を取得し、DBMS_OUTPUT.PUT_LINEで出力してみる。
declare
resp dbms_cloud_types.resp;
begin
resp := dbms_cloud.send_request(
credential_name => 'AWS_CREDENTIAL_NAME',
uri => 'https://[バケット名].s3-[リージョン名].amazonaws.com/testdata_00.txt',
method => dbms_cloud.method_get
);
dbms_output.put_line(
dbms_cloud.get_response_text(resp)
);
end;
/実行結果は以下の通りとなる。
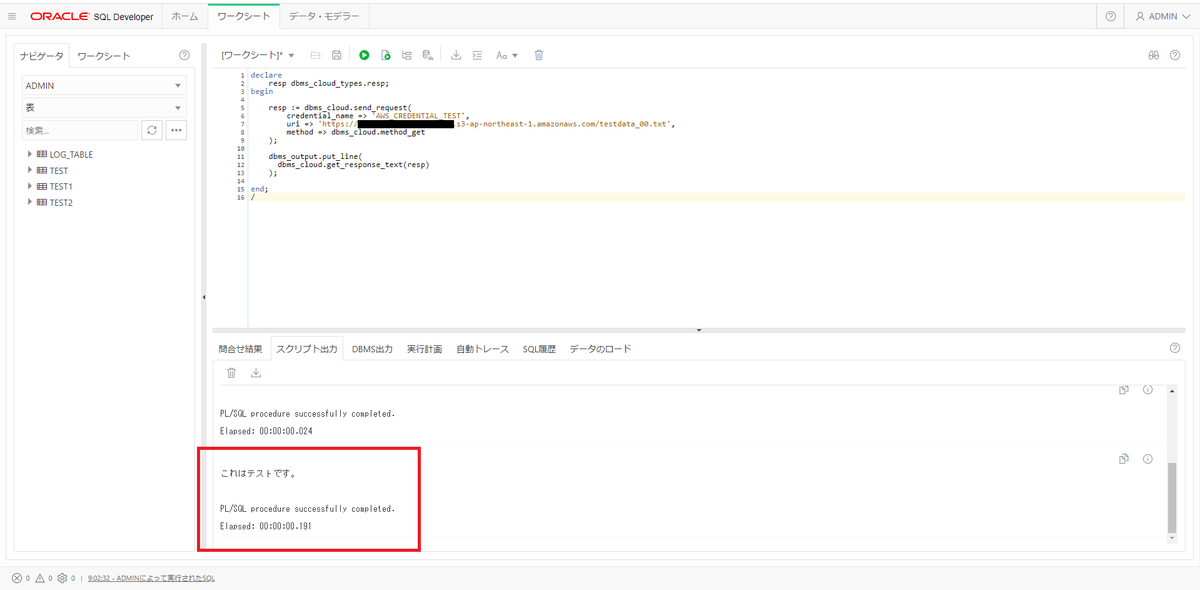
おお! ちゃんとファイルの中身が見えるのが確認できた。
DBMS_CLOUD.COPY_DATAを使って取り込んでみる
同じ要領で今度は以下のようなデータを用意する。
ID|NAME
4|test4
5|test5
6|テスト六郎これを「testdata_01.txt」としてS3にアップロード。
オブジェクトURLはhttps://[バケット名].s3-[リージョン名].amazonaws.com/testdata_01.txtとなる。
今度はDBMS_CLOUD.COPY_DATAというのを使って実際にテーブルに取り込んでみる。
取り込み先のテーブルとして以下のような非常に簡単な(testdata_01.txtと同じ形式の)テーブルを用意する。
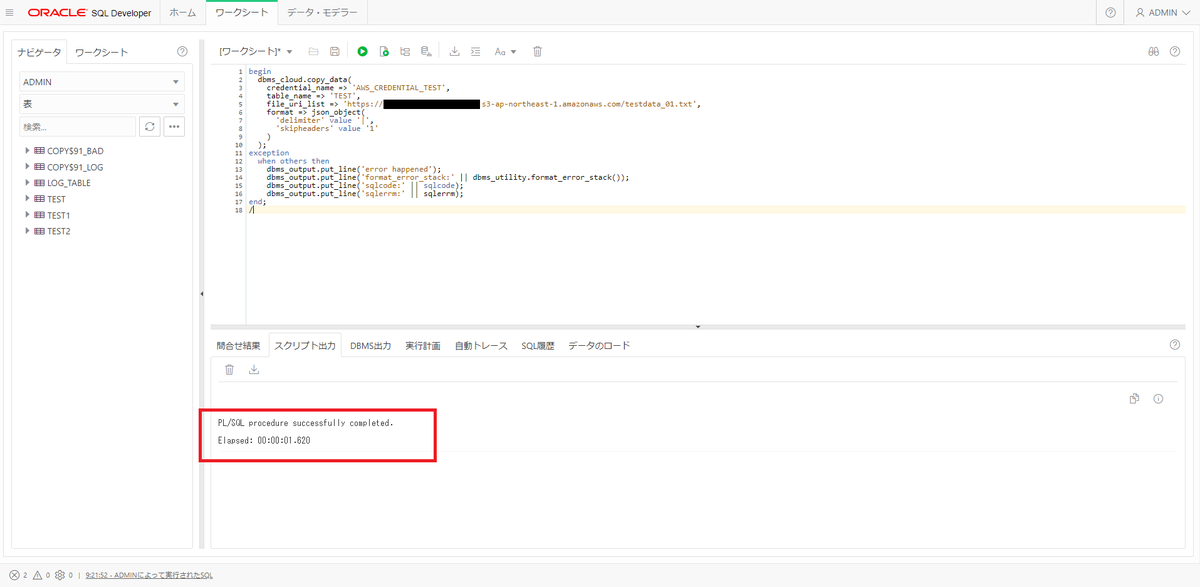
create table test(id number, name varchar2(100));DBMS_CLOUD.COPY_DATAを実行する。
begin
dbms_cloud.copy_data(
credential_name => 'AWS_CREDENTIAL_TEST',
table_name => 'TEST',
file_uri_list => 'https://[バケット名].s3-[リージョン名].amazonaws.com/testdata_01.txt',
format => json_object(
'delimiter' value '|',
'skipheaders' value '1'
)
);
end;
/
formatという引数は元ファイルのファイル仕様を指定するものである。 内容はJSON_OOBJECTファンクションを使って、「‘KEY名’ value ‘値’」のかたちで設定することになる。 上のコード例で指定しているdelimiterは「データの区切り文字」で、今回はパイプ(”|“:U+007C。ADWのCOPY_DATAはデフォルトのデリミタがこれなので今回それに倣っている)。 skipheadersはヘッダ行として読み込み対象からスキップする行数で、今回は1(1行目がヘッダなので)。 その他の詳細はここに載っている。 指定できるパラメータ値を見る限りだとなんとなくSQL Loaderの設定ファイルを連想させる(内部的にSQL Loaderでも動かしてるのかな?)
このあとTESTテーブルの中身見てみると…

おお!! testdata_01.txtとして中身に記述した3件がはいっていることが確認できた。
S3 Object Put -> Lambda -> ADWの連携をしてみる
せっかくなのでもう少し広げてみようと思う。 S3へのオブジェクトPUTをトリガーにしてLambdaを動かし、LambdaからADWに接続してS3のオブジェクトを取り込んでみる。 Lambda→Oracle ADWへの接続は前回の記事をそのまま流用する。
S3-Put TriggerをLambda関数に設定する
Lambda関数のトリガーを設定する。
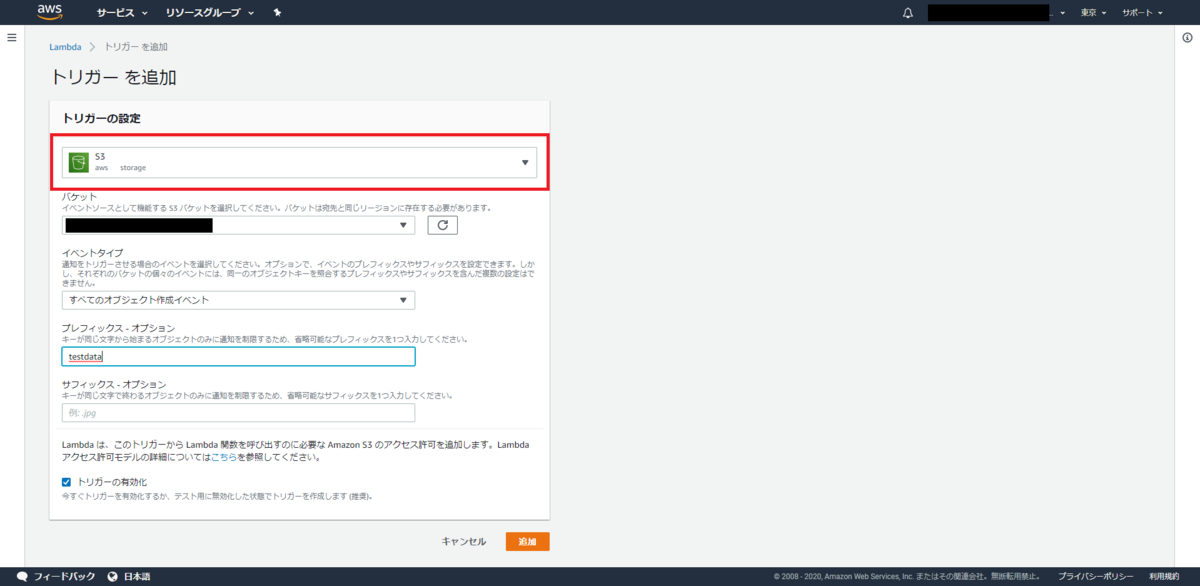
バケットは前回の記事でつかってたやつを選択する。 あと、今までの流れに倣ってプレフィックスをtestdataにしておく。 先頭が”testdata”で始まるファイルをPUTしたときにトリガーとして起動されるように設定するのだ。 (ただこれにはあまり強い意味はない…なんでもかんでもS3 PUTイベントを流す対象にすべきではないと思ったからあえて設定しているだけである。好きな値にすればいいと思う)
また、テストイベントを設定しておく。 テストイベントの設定で発生するeventオブジェクトの中身が大体わかるからである。 S3-Putでは以下の構造のオブジェクトが渡ってくるらしい。
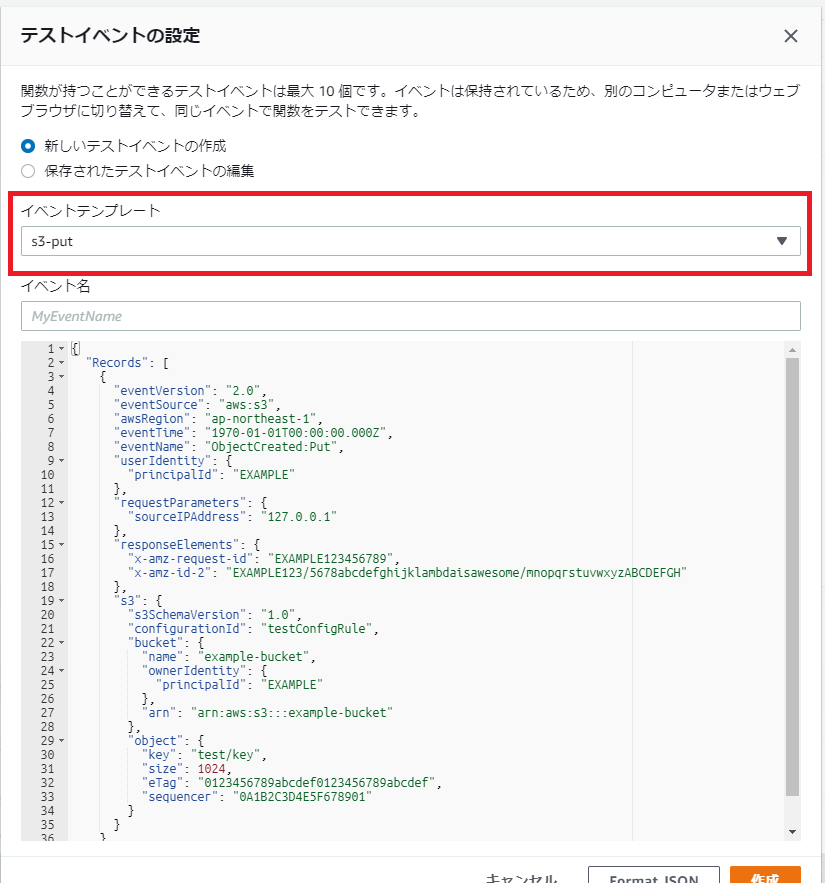
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "ap-northeast-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "example-bucket",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::example-bucket"
},
"object": {
"key": "test/key",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}Oracle ADWのDBMS_CLOUD.COPY_DATAに必要なのはオブジェクトのURIである。
URIの形式はhttps://[バケット名].s3-[リージョン名].amazonaws.com/[オブジェクトKEY]だったから、必要そうなのは
- Records[n].awsRegion
- Records[n].s3.bucket.name
- Records[n].s3.object.key
の3つのようだ。 とりあえずこの構造をメモしておく。
Lambda関数のHandlerを作成する
前回の記事の続きで、plsql.jsというファイルを以下のように新たに用意する。
const oracledb = require('oracledb');
module.exports = async (event) => {
try {
console.log(JSON.stringify(event)); // 念のため(?)
let awsRegion = event.Records[0].awsRegion;
let s3bucketName = event.Records[0].s3.bucket.name;
let s3objectName = event.Records[0].s3.object.key;
let s3uri = `https://${s3bucketName}.s3-${awsRegion}.amazonaws.com/${s3objectName}`;
console.log(s3uri); // 念のため(?)
console.log('START:CONNECTION');
let con = await oracledb.getConnection({
user : 'ADMIN',
password : '[ADMINユーザーのパスワード]',
connectString: 'hogeadwtest_low'
});
console.log('START:SELECT');
let result = await con.execute(`
begin
dbms_cloud.copy_data(
credential_name => 'AWS_CREDENTIAL_TEST',
table_name => 'TEST',
file_uri_list => '${s3uri}',
format => json_object(
'delimiter' value '|',
'skipheaders' value '1'
)
);
end;`);
return result;
} catch(err) {
console.log('error happened');
throw err;
}
};基本的に前回のselect.jsと変わっていない。 node-oracledbのgetConnectionで取得したConnectionオブジェクトのexecuteメソッドに、select文ではなくbegin~end;で記述されるPL/SQL文を入れただけである。 PLSQLの中身は↑で書いたDBMS_CLOUD.COPY_DATAの実験時に使ったものと同じ。
DBMS_CLOUD.COPY_DATAのfile_uri_listには、S3のオブジェクトURIを設定する。 これはS3へのオブジェクトPUTイベントから必要なフィールド(上で書いた3つ)を取り出してURIの形式に整形した変数で実現する。
なお、イベントオブジェクトの先頭のRecordsは配列のようなので、複数のオブジェクトPUTがあった場合は複数の要素が入ってくるのだろうと予想するが、ここでは面倒なので実験のため一番最初の要素だけを取り出して扱うことにする(ただまあ処理の中身をforeachとかで囲ったりするだけでほとんど手を入れることなく利用できる気はする)
ついでにこのplsql.jsを呼び出すハンドラーindex2.jsを以下のように作る。
const plsql = require('./plsql.js');
exports.handler = async (event) => {
console.log('START');
let result = await plsql(event);
console.log(result);
const response = {
statusCode: 200,
body: JSON.stringify(result)
};
console.log('END');
return response;
};これは単に入り口として用意しただけにすぎない。 処理の実態はplsql.jsに依存しているからだ。 面倒なら前回のindex.jsを改造してもよいと思う。
Lambdaにdeploy
前回同様、ファイルサイズの関係で、S3にアップロードして使う。 面倒くさいので(?)CLIで一気にがーっとやっちゃうことにする。
zip -r lambda.zip ./*
aws s3 cp lambda.zip s3://[バケット名]/lambda.zip
aws lambda update-function-code --function-name [ラムダ関数名] --s3-bucket [S3バケット名] --s3-key lambda.zipまた、ハンドラーの設定を変える。 デプロイファイル容量が大きいと画面でハンドラーを変更できなくなるようなのでこれもAWS CLIで変更する。
aws lambda update-function-configuration --function-name [ラムダ関数名] --handler index2.handlerファイルを用意する
testdata_02.txtを以下のように用意する。
ID|NAME
7|テスト七郎
8|テスト八郎
9|テスト九郎S3にアップロード。 面倒くさいのでここもCLIにする。
aws s3 cp testdata_02.txt s3://[バケット名]/testdata_02.txt連携確認する
aws s3 cpコマンド実行後にAWSでCloudWatchを覗いてみる。
Lambda関数のトリガーが適切に設定されている前提ならちゃんと動いているのを確認できるはずである。
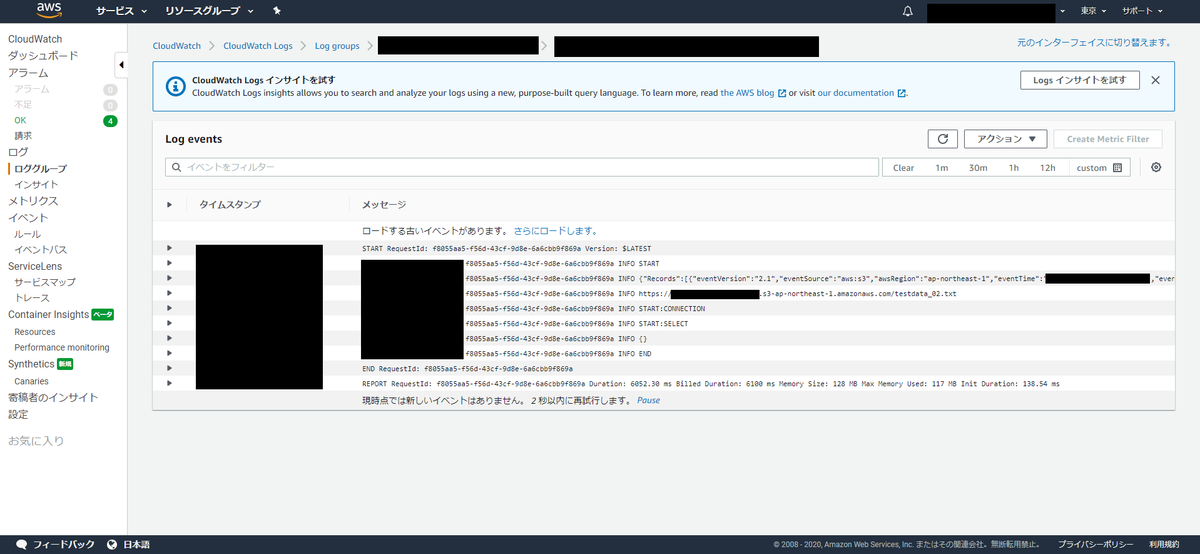
余談だが日和見でいれたconsole.logのミス(?)にここでようやく気づいた。 PLSQL実行するのに”START:SELECT”って何やねん。。。 まあ大勢に影響はないので無視する。
ついで、Oracle ADWでデータが入ったかどうかSELECTしてみる。
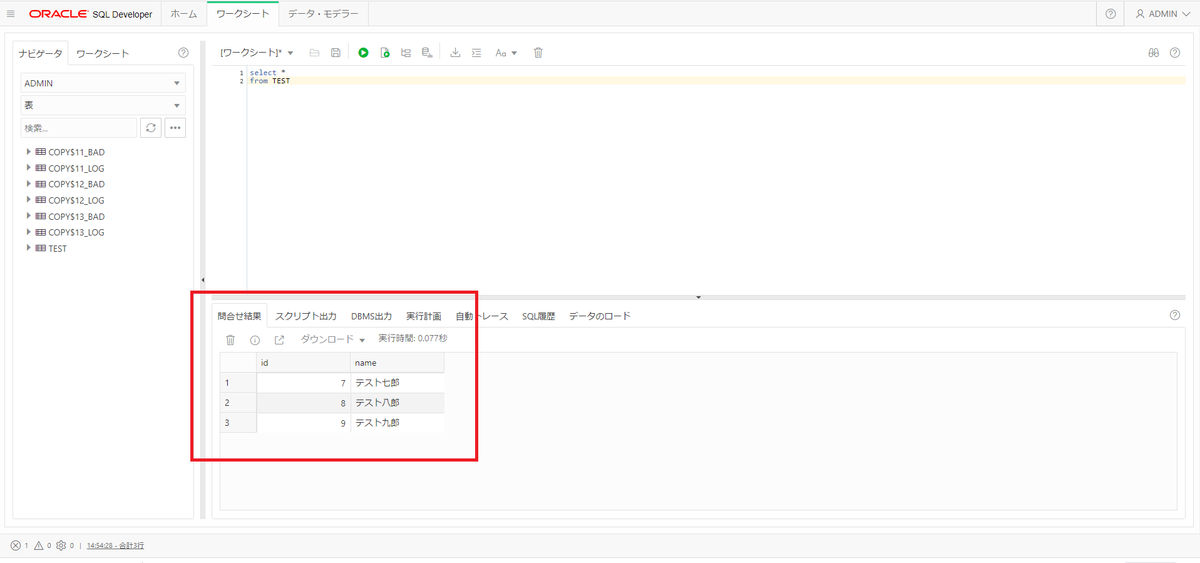
おお~。 S3へのPUTをトリガーに、自動的にOracle ADWまでデータが取りこまれていることが確認できた。
おわりに
前回の記事ではLambda→Oracle ADWの接続確認に過ぎなかったが、今回、それに加えて、Oracle ADWの機能を少し活用できたのは、個人的に良かったと思う。 両者を連携させることによる面白み?が生まれたと思う。
今回のキモはDBMS_CLOUD.CREATE_CREDENTIAL→DBMS_CLOUD.SEND_REQUEST or DBMS_CLOUD.COPY_DATAの箇所だろう。 CLIを使わずに、自前でやろうとすると、やたら面倒くさいクラウドのREST APIを、ユーザー・パスワード設定するだけで後は良しなにやってくれる、DBMS_CLOUDパッケージは便利だな、と感じた。 やってないけどAzureもこんな要領で比較的簡単につながりそうだな。 そのうち試してみよう。
そしてそういう意味でも、最後のS3→Lambda→Oracle ADWは本当に「オマケ」である。 そこまでで実験確認できた内容の、ただのちょっとした応用にしかならなかった。 エラーハンドリングとかも適当だし、実用化にあたっては、この辺はもう少しじっくり考える必要があるだろう。 面倒くさいので(何回も言ってるがw)一旦今回の「連携が確認できた」という段階でこの記事は締めることにするが、前回の記事の深堀も含めて、そのうち残りをやってみたいなあ。