【Oracle Cloud】Object Storageへのオブジェクト格納→Event→Functions→ADWをNode.jsランタイムでつくってみた
タイトルの通り。
Oracle CloudのサーバレスOracle Functionを使って、よくある流れ
- Object Storageにデータが格納される
- データ格納されたことを受けてEventが発行される
- 発行されたEventをトリガーにFunctionが起動される
- FunctionがデータをADWに格納する
を、Node.jsランタイムでやってみたので、その記録。
- はじめに
- (0)事前準備
- (1)Oracle ADWでCredential+テスト用テーブルを作成
- (2)Oracle ADWのWalletをダウンロード
- (3)Object Storageのイベント出力をONにする
- (4)functionの作成 - アプリケーション
- (5)functionの作成 - source
- (6)functionの作成 - Dockerfile
- (7)functionの作成 - deploy
- (8)functionの設定(環境変数)
- (9)functionの設定2(メモリサイズとタイムアウト)
- (10)loggingの設定
- (11)イベントの作成
- (12)実行
- おわりに
はじめに
初めに言っておくと、冒頭の1.~4.の流れを実行するサンプルは、Oracle Functionのgithubにサンプルコードとして転がっている(ランタイムはpython)。
https://github.com/oracle/oracle-functions-samples/tree/master/samples/oci-load-file-into-adw-python
なので、単に1.~4.をやりたいんです言語は問いません、だったらこれをほぼ丸パクリすればなんとかなる。
(ただこのサンプルはORDS使ってるので若干癖があるような気もする)
ちなみにそれ以外にもいろんなユースケースのサンプルが用意されている
https://github.com/oracle/oracle-functions-samples
でもPythonとJavaしかないのだ。
俺の好きなNode.jsがない。
というわけでNode.jsで作ってみることにした。
(0)事前準備
要は環境構築。
以下が必要。
- oracle cloudのアカウントが存在すること
- 加えて、連携機能のINPUTになるObject Storage、OUTPUTになるOracle ADWがそれぞれ最低1つ必要
- oci cliがインストールされていること
- ただインストールされているだけじゃなくoci cliを使ってOCIリソースへアクセスできるようになっていること。要するにAPIキー発行が終わってること
- oracle functionを利用するためのポリシー設定等が済んでいること
- docker cliがインストールされていること
- fn cliがインストールされていること
下記のあたりが参考になる。
https://qiita.com/Brutus/items/e9511d23d2ba3e88d2ea
https://cloudii.atomitech.jp/entry/20200717/1594952234
ちなみに私はVirtual Box上のOracle Linux 7.8の環境で一通りやりました(oci cli、docker cli、fn cli他インストール)が、↑の記事の手順で紹介されているOracle Cloud Developer ImageのVMは初っ端からDocker入ってたりするので、こっち使う方が楽です。
(手元のOracle Linux 7.8を前から使ってて、dockerやら何やらがもういろいろ入ってた都合で、VM使うって発想にならなかった。。。)
(1)Oracle ADWでCredential+テスト用テーブルを作成
冒頭で紹介したサンプルコードだとORDSを使ってるのだが、ここではDBMS_CLOUD.COPY_DATAを使うことにする。
これは前回までにやっていたAWS S3との連携実験の流れをそのまま使いたかったからなのだが。
このためAPIキーの発行(これはOCI CLIを入れてれば実施済みのはず)とCREDENTIALの作成等が必要になる。
Oracle ADWのSQL Developer Webに入る。
ADWを選択肢て「サービス・コンソール」→「開発」

ADMINでログインして以下SQLを実行する。
begin dbms_cloud.create_credential( credential_name => '[適当なCREDENTIAL名]', user_ocid => '[APIキーを発行したユーザーのOCID]', tenancy_ocid => '[テナンシーのOCID]', private_key => '[秘密鍵の内容]', fingerprint => '[管理コンソール上で表示されているfingerprint]' ); end; /
秘密鍵は先頭行に-----BEGIN RSA PRIVATE KEY-----及び最終行に-----END RSA PRIVATE KEY-----を含め、途中の改行はあってもOK(ただここはツールによるかも。SQL Developer Webなら大丈夫)
作成後に以下のSQL(ADMINユーザーで実行)すると作成が確認できる
select * from dba_credentials
また、今回の検証で出力先となるテーブルを作成する。
非常に簡単にこんな↓テーブルを。
create table test4function(id number, name varcar2(100));
(2)Oracle ADWのWalletをダウンロード
ADWを開いて「DB接続」ボタンをクリックする

「ウォレットのダウンロード」をクリックする。
パスワードはまあなんか適当に。(今回は使わない)
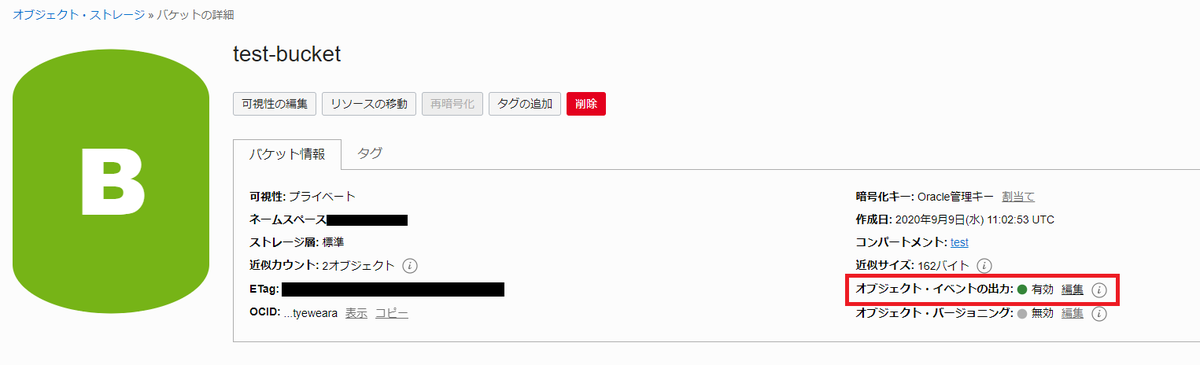
(3)Object Storageのイベント出力をONにする
まずは適当にバケットを一つつくる。
作成後、バケットの詳細画面に遷移し、「オブジェクト・イベントの出力」の「編集」をクリックする
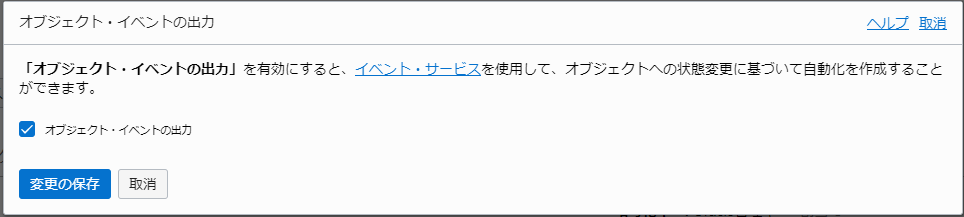
「オブジェクト・イベントの出力」を有効化する。
(4)functionの作成 - アプリケーション
まずはfunction(関数)群の塊を管理するアプリケーションというのを作る。
開発者サービス>ファンクションを選択
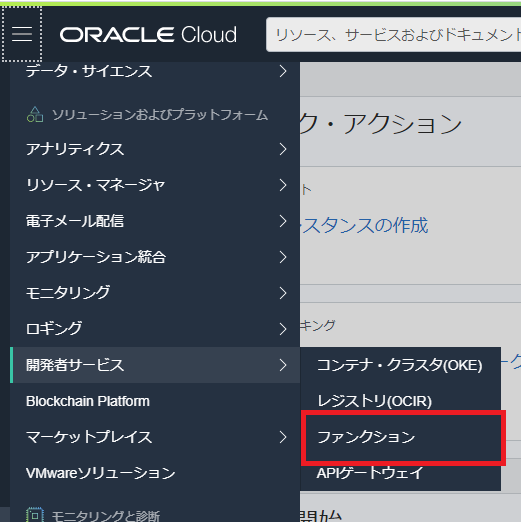
「アプリケーションの作成」をクリック

名前を入力し、VCN、サブネットを選択する。

LambdaだとVPCへの接続設定はオプションだった認識だが、こっちは絶対指定させる必要があるようだ。
そのネットワーク内でFunctionのコンテナを動かすことを前提にするということか。
多分そうだろうな。(未確認)
やったことないのでわからないが、ここでprivate subnetを選択した場合は、ルートテーブルにNAT Gatewayを関連付けてないと、外に出れないので、インターネットに出るような
処理(例えばNode.jsでいえばaxiosで外にリクエストを投げるようなケース)が悉く失敗すると思われる。
先にそっちをやっておきましょう。
(5)functionの作成 - source
作業するサーバ上の適当な作業場所に移動し、functionをつくってソースを用意してDockerイメージつくる。
> fn init --runtime node test-adw-node-func
> cd test-adw-node-func
npm init→npm installしてNode.jsプロジェクトのベースを用意する。
> npm init > npm install --save oracledb @fnproject/fdk
(2)でダウンロードしたウォレットファイルを配置する。
ローカルからサーバのこの場所へscp等して持ってきてください。
> ls Wallet_TESTADW.zip Wallet_TESTADW.zip
plsql.jsというjavascriptファイルをつくる
> vi plsql.js
const oracledb = require('oracledb'); module.exports = async (config , objectUri) => { try { let conn = await oracledb.getConnection({ user: config.username, password: config.password, connectString: config.connectString }); let result = await conn.execute(`begin dbms_cloud.copy_data( credential_name => '[↑でつくったCREDENTIAL名]', table_name => 'TEST4FUNCTION', file_uri_list => '${objectUri}', format => json_object( 'delimiter' value ',', 'skipheaders' value '1' ) ); exception when others then raise; end;` ); return result; } catch(err) { throw err; } };
引数にconfigというオブジェクト(中身はDB接続情報)と取り込むObjectのURIをもらってDBMS_CLOUD.COPY_DATAを実行するだけの簡単な処理。
CREDENTIAL名、取り込み先テーブル名等、DBMS_CLOUD.COPY_DATAの他のパラメータも引数(オブジェクト)化してより汎用的な作りにもできるが、まあ、一旦この段階ではこの程度にしておく。
あと結果を取るためのselect.jsというのもつくる
const oracledb = require('oracledb'); module.exports = async (config) => { try { console.log('GetConnecttion START'); let con = await oracledb.getConnection({ user : config.username, password : config.password, connectString: config.connectString }); console.log('GetConnecttion END'); console.log('Select START'); let result = await con.execute(`select * from TEST4FUNCTION`); console.log('Select END'); return result; } catch(err) { console.log('error happened'); throw err; } };
基本的なつくりはplsql.jsと同じ。
TEST4FUNCTIONテーブルに入ってるデータを全部selectして結果を呼び出し元に返すだけ。
最後にこれらを呼び出すようfunc.jsを以下のように変更する。
const fdk=require('@fnproject/fdk'); const plsql = require('./plsql.js'); const select = require('./select.js'); fdk.handle(async function(input){ try { let config = { username : process.env['username'], password : process.env['password'], connectString : process.env['connectString'] }; console.log(`username:${config.username}`); console.log(`password:${config.password}`); console.log(`connectString:${config.connectString}`); // plsql execute let objectUri = `https://objectstorage.ap-tokyo-1.oraclecloud.com${input.data.resourceId}`; console.log(`object uri:${objectUri}`); let plsqlResult = await plsql(config , objectUri); // result data select let selectResult = await select(config); console.log('select result:'); console.log(JSON.stringify(selectResult)); return JSON.stringify(selectResult); } catch(err) { console.log('error happened'); console.log(err.stack); throw err; } })
fn initで初期の関数を作成直後には、fdk.handleの引数のfunctionにはasync修飾子がついていないが、oracledbを使ってデータを投入及びselectする都合上、どれにもasyncをつけるので、全ての呼び出し元である親玉のこいつにもasyncをつける。
なお、DBの接続ユーザー、パスワード、接続文字列はprocess.envから、つまり環境変数から取っているが、これについては後述する。
引数のinputは呼び出し元から渡されるJSONオブジェクトである。
今回のケースでは「Object StorageにデータがPUTされた」ことがEventとして発行され、funcitonのトリガーとなる。
ちなみに実際中身をJSON.stringifyで見てみたところこんな感じ↓だった
"{\"eventType\":\"com.oraclecloud.objectstorage.updateobject\", \"cloudEventsVersion\":\"0.1\", \"eventTypeVersion\":\"2.0\", \"source\":\"ObjectStorage\", \"eventTime\":\"2020-09-14T06:25:20Z\", \"contentType\":\"application/json\", \"data\":{ \"compartmentId\":\"ocid1.compartment.oc1..xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"compartmentName\":\"test\", \"resourceName\":\"function_testdata/testdata01.csv\", \"resourceId\":\"/n/nxxxxxxxxxxx/b/test-bucket/o/function_testdata/testdata04.csv\", \"availabilityDomain\":\"NRT-AD-1\", \"additionalDetails\":{ \"bucketName\":\"test-bucket\", \"versionId\":\"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"archivalState\":\"Available\", \"namespace\":\"nxxxxxxxxxxx\", \"bucketId\":\"ocid1.bucket.oc1.ap-tokyo-1.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\\", \"eTag\":\"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\" } }, \"eventID\":\"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"extensions\":{ \"compartmentId\":\"ocid1.compartment.oc1..xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\" } }"
ので、input.data.resourceIdの部分でベースURI以下のパスは補完できる。
これを使ってfunc.js内でplsql.jsに渡すObject URIを
let objectUri = `https://objectstorage.ap-tokyo-1.oraclecloud.com${input.data.resourceId}`;
のように編集している。
(6)functionの作成 - Dockerfile
通常fn initした直後の関数ディレクトリにはDockerfileは含まれないが、意図的に用意するこで、fn projectで作られるイメージを変更(カスタマイズ)できる。
ここでは以下のようなDockerfileにする。
FROM oraclelinux:7-slim
# install oracle instant client & nodejs
RUN yum -y install oracle-release-el7 oracle-nodejs-release-el7 && \
yum-config-manager --disable ol7_developer_EPEL && \
yum -y install oracle-instantclient19.8-basiclite nodejs && \
rm -rf /var/cache/yum
WORKDIR /function
# add node sources
ADD func.js /function/
ADD func.yaml /function/
ADD package-lock.json /function/
ADD package.json /function/
ADD plsql.js /function/
ADD select.js /function/
RUN npm install
# add wallet
RUN yum install -y unzip
ADD Wallet_TESTADW.zip /function/
RUN mkdir -p /function/wallet/network/admin
RUN unzip /function/Wallet_TESTADW.zip -d /function/wallet/network/admin/
ENV ORACLE_HOME=/function/wallet
# group add
RUN groupadd --gid 1000 fn && \
adduser --uid 1000 --gid fn fn
# execute
ENTRYPOINT ["node", "func.js"]
下記のページ↓を参考に、ソースファイルの移動とunzip追加(ウォレットファイル解凍のため)している程度の変更を加えているだけである。
https://docs.cloud.oracle.com/en-us/iaas/Content/Functions/Tasks/functionsrunningasunprivileged.htm
以下少し補足すると。。
- Oracle Instant Clientのバージョンは検証時点の最新である19.8を指定している。
- Oracleへの接続ライブラリは
$ORACLE_HOME/network/admin/tnsnames.oraを見て接続識別子を決めるので、Dockerfile内でこの環境変数をセットしている。 groupadd --gid 1000 fn && adduser --uid 1000 --gid fn fnのところは、Dockerキャッシュが残ってると2回目以降失敗することがある(そのユーザーもういるんだけど、と怒られる) fn projectではfn deployでDockerイメージのビルドを行うが、この際--no-cacheオプションをつける→fn deploy --no-cache --app test-appと、Dockerキャッシュを無視できるので、ここでエラーが起きる場合は、--no-cacheオプションをつけてビルドするとよい。
ベースイメージについて
fn projectでランタイムをNode.jsにすると、プリビルドイメージとしてfnproject/nodeというのがpullされて、Dockerfileを指定しない場合はこいつの上でコンテナが動く形になるようだ。
このイメージ、ここによると、Alpineをベースに作られてるらしく、中身は基本Node.js以外入ってないすっからかんのイメージだった(まあ当たり前か)
このイメージをベースにする場合、要するに「AlpineからOracleに接続する」環境を整える必要があり、様々な関連ライブラリをapkでインストールしなければならず、非常に面倒くさい。
しかもnode-oracledbのgithub issueで「Alpineはサポートしてないんだよなあ」とかいう発言を見かける始末。
ので、やめた。
実際上記で記載した参考ページの内容見る限りでもイメージの元ネタはoraclelinux:7-slimを使っている。
せっかくならfnproject用に用意されたNode.jsのイメージを使いたかったが…
個人的には、oraclelinux使うんだったら最早FN Project関係なくてただのDockerコンテナつくってるだけじゃんと思ってしまう。
実際最下部のENTRYPOINTの部分外せば「Oracle Instant Client(19.8)とNode.jsの入ったOracleLinux」のコンテナとして普通に動作する。
ただまあ逆に言うならこういう風にイメージを自由に選択・カスタマイズできるのもFN Projectの強みでもあるのか。
既存のDockerイメージを使いまわせますというのも見たしな。
イメージの軽量化について
このやり方で固めたイメージは大体250~260MBになる。
やはりそこそこ重い。
↑に挙げたサンプルコード(例えばこれなど)を参考にすると、Instant ClientをObject Storageに置いといて、WalletファイルはADBから動的に、それぞれアプリケーションから取得・解凍して扱うやりかたが載っている。
特にInstant Clientのほうはライトパッケージだとしてもそこそこ重いので、こいつをイメージから除外できると軽量化が進むと思う。
その分アプリケーション側で頑張る部分が増えてくるが。
あとそもそもfn projectのNode.js実行用プリビルドイメージfnproject/nodeを頑張って育てるのもいい気がする。
今回使ったoraclelinux:7-slimは素の状態でも131MB程だが、fnproject/nodeは75.5MB程度で、最初からすでに半分くらいの容量の差が出ている。
とはいえ必要なものをかき集めるためにapkしまくったら結局ぶくぶく太っていくのだと思われるが、やってみる価値はありそうな気はする。
(7)functionの作成 - deploy
関数ディレクトリ配下で、以下のコマンドを実行してdeployする。
> fn deploy --app [アプリケーション名]
アプリケーション名は適宜各自の環境に合わせて変えて下され。
(関数名ではなく、その関数群を束ねている「アプリケーション」なので注意)
やってることはほとんどdocker buildとdocker pushで、実際
> fn --verbose deploy --app [アプリケーション名]
と、--verboseオプション(短縮形は-v)付けるとDocker buildの様子が標準出力されるのを確認できる。
ビルドでエラーになるようなケースではこのオプションをつけてdocker buildの様子を確認したほうが良い。
fn deployコマンドでは、これに加えてOracle Cloud側のFunctionの対象イメージを更新したりとかやってるみたいである。
ちなみにDockerキャッシュを無効化する場合は--no-cacheオプションをつけて以下のように
> fn deploy --no-cache --app [アプリケーション名]
実行できる。
また、標準(オプション未指定)だと、func.yamlに記述されているversion番号を1ずつインクリメントしていく(仮にDocker buildが失敗しても1インクリメントされる)ので、fn deployするたびに新しいVersionのイメージが1つ別に作られる形になる。
これが鬱陶しい場合は--no-bumpオプションをつけて以下のように
> fn deploy --no-bump --app [アプリケーション名]
実行でき、この場合、出来上がるイメージのVersionは、実行前にfunc.yamlのversionに記述されている値と一致する(既存イメージを上書き更新する形)
(8)functionの設定(環境変数)
環境変数を設定する。
アプリケーションで使用することになっていたDBの接続ユーザー、接続パスワード、接続文字列を指定する。
CUIだと
> fn config func [アプリケーション名] [関数名] [環境変数名] [環境変数値]
で設定する。
例えばユーザーはアプリケーションでusernameというキーで値を取得していたので
> fn config func test-app test-adw-node-func username ADMIN
で設定する。
ただ2020年9月現在、これはもはやOracle Cloudの管理コンソール上で(つまりGUIで)設定できて、ファンクション>(アプリケーション名)>(該当のfunction名)>構成をクリックする
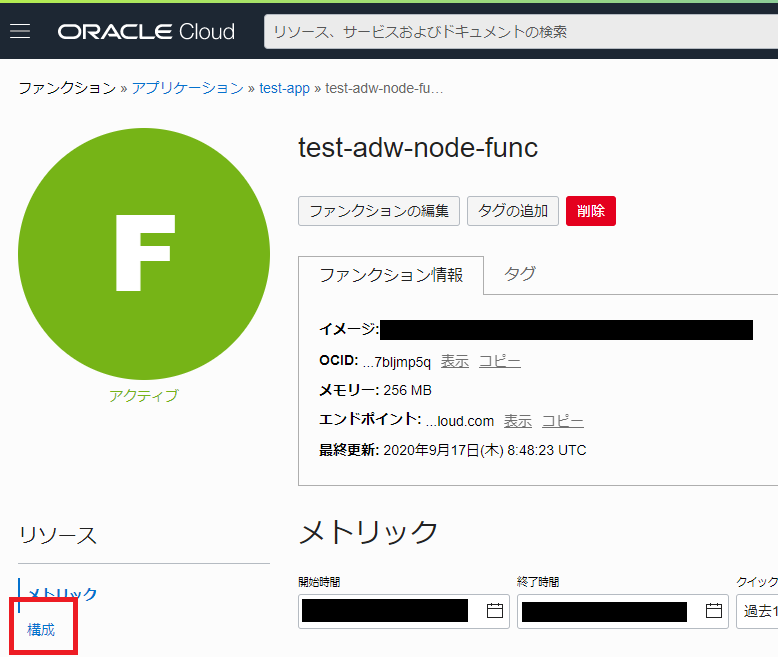
と、「キー」「値」のペアで入力・編集ができるようになっている。

画面上の表記が「構成」であることや、fn projectのサブコマンド名も「config」であることなどから、どうしても「環境変数」っぽくない印象を個人的には受けてしまうのだが、実際のところアプリケーション内では環境変数として取り扱うことができる。
この設定はAWS Lambdaの環境変数とほぼ同質のものだろう。
サーバレスアプリケーションの動作を制御するために設定する環境変数値という理解でよいはずだ。
今回はDB接続情報を設定しているが、実際のところ他にもいろいろ使い方はあるはずで、例えば「LambdaからOracle ADWに接続してみた」の回でLambdaに設定したように、LD_LIBRARY_PATHを無理やり上書きしてみることなども可能だ。
Lambdaと違うのは、Dockerfileを自分で作れるので、Dockerfile内のENV定義と重複する可能性があるということか。
今回も(今さら気づいたが)
ENV ORACLE_HOME=/function/wallet
と、Dockerfile内でORCLE_HOMEという環境変数値を設定しているので、functionそのものに設定してはいないが、コンテナとしてはこの環境変数値は有効に動作する。
設定箇所が分散するのはわかりづらいので、Dockerfileでやるか、fn configでやるか、設定箇所を統一させたほうがいいだろう(と自分に言い聞かす)
(9)functionの設定2(メモリサイズとタイムアウト)
これとは別にfunction固有の設定としてメモリサイズとタイムアウト時間を指定する。
こっちはCLIだとfn updateというサブコマンドを使う。
メモリの場合は
> fn update func [アプリケーション名] [関数名] --memory 256
等と指定する。
最後の数値の単位はMB。
なお、2020年9月時点だと、128・256・512・1024が選べる(逆に言うとこの中からしか選べない)
タイムアウトは
> fn update func [アプリケーション名] [関数名] --timeout 120
等と指定する。
最後の数値の単位は秒。
なお、2020年9月時点だと、30・60・90・120が選べる(逆に言うとこの中からしか選べない)
function作成直後の初期値は、メモリ128MB・タイムアウト30秒に設定されている。
実体験では、128MBだとメモリエラーが起きたのと、タイムアウト30秒だとタイムアウトした経験があるので、それぞれ256MB・120秒に設定した。
メモリはともかくタイムアウト時間が120秒(2分)というのが痛いところ。
AWS Lambdaは15分までいけるので、短すぎるという印象である。
今後この数値が伸びていくことを期待したい。
(10)loggingの設定
ロギング>Logsメニューを選択。
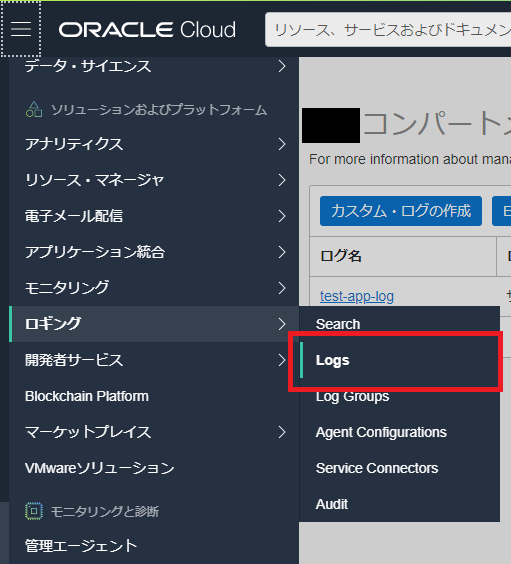
「ログ・グループ」→「ログ・グループの作成」を選択して、ログ・グループを作成する。
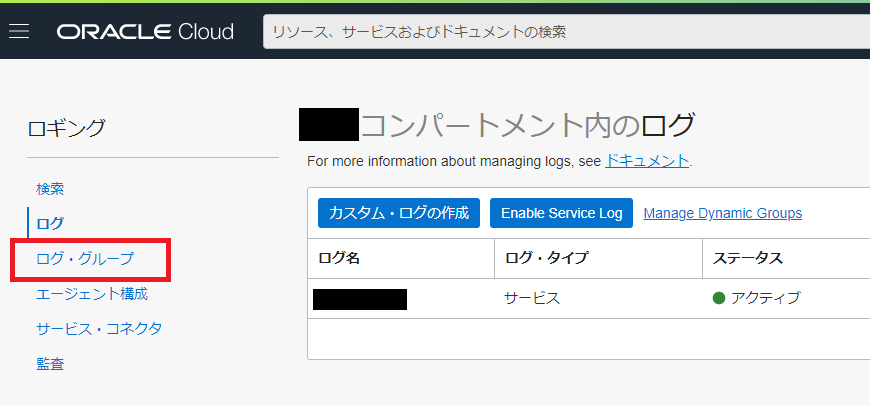
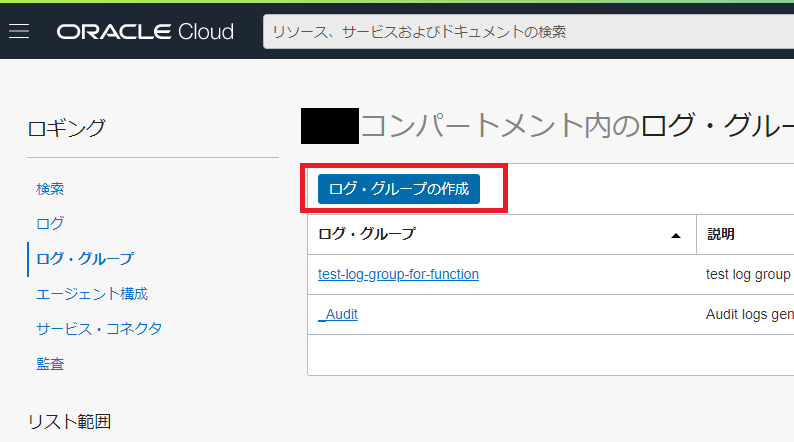

対象のコンパートメントと名前、説明をいれるだけで、これは「枠」というか器の定義の設定みたいなものである。
続いてログ>「Enable Service Log」を選択して、サービスログ定義を作成する。

「サービス」は「Functions」を
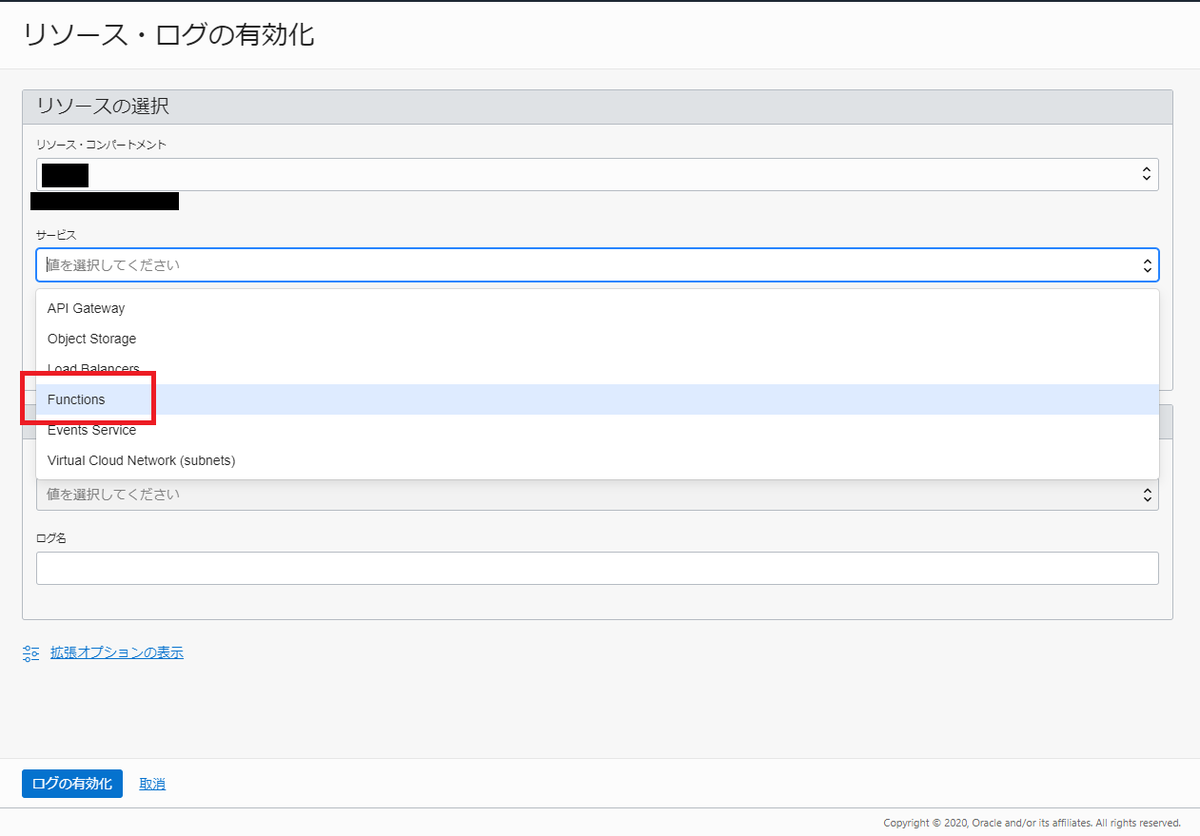
「リソース」は今回作成したアプリケーションを

「ログ・グループ」に↑でつくったログ・グループを
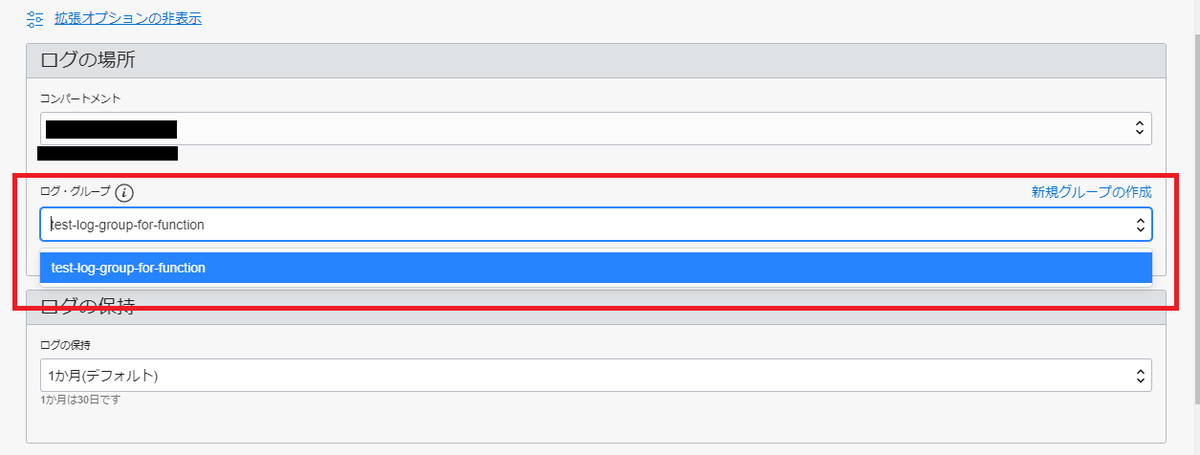
必要とあらばログの保持期間等を変更して、最後に「ログの有効化」ボタンをクリックする。
(11)イベントの作成
Functionをトリガーするためのイベントを準備する。
アプリケーション統合>イベント・サービスを選択
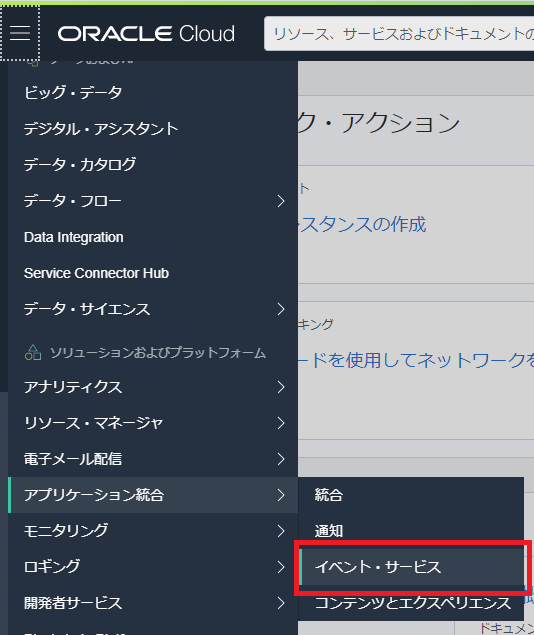
「ルールの作成」をクリック

「ルール条件」の欄で、条件→「イベント・タイプ」、サービス名→「Object Storage」を選択
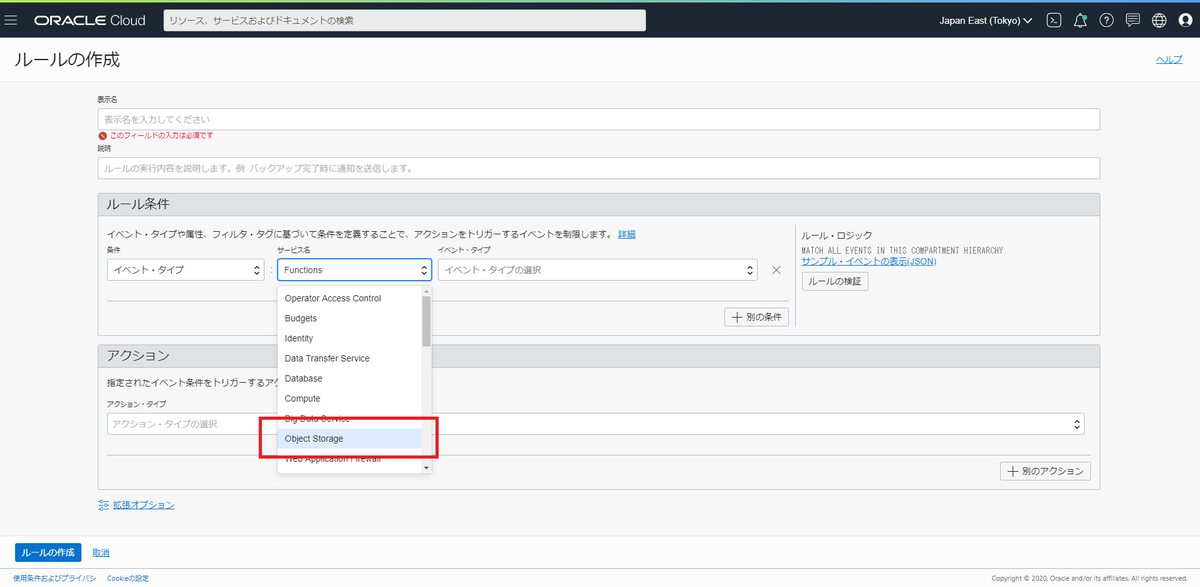
「イベント・タイプ」から「Object - Crate」、「Object - Updatte」を選択


「+別の条件」ボタンを押して条件を追加する。
今度は条件→「属性」を選択
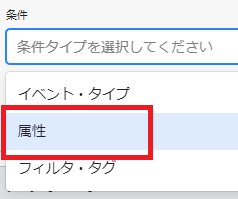
属性名→「bucketName」を選択

属性値→(3)のバケット名を入力。

同じ要領で、属性名→compartmentNameにも同様の条件を追加する。
こうすることで「指定のコンパートメントの指定のバケットにObjectがCreate/Updateされたとき」に条件を限定できる。
ただ、ここまでの条件でもAWS S3のPUTトリガーに比べるとまだ大分条件が緩くて、要するにこの条件だと「そのバケットに入ってくるオブジェクトは全部が対象」になってしまう。
しかし、この検証したときにはなかった(と記憶している)のだが、属性名に「resourceName」という項目が増えているのに(このブログ記事を書いてる途中で)気づいた
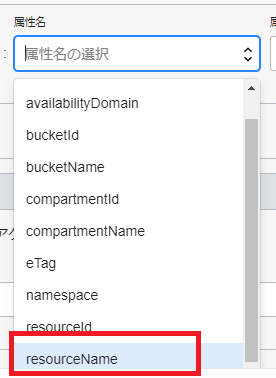
これを指定すれば特定のオブジェクト名に対象を限定させられるかもしれない。
ただし属性名を見る限りではPrefixではないので、つまりオブジェクト名の前方一致ではなく完全一致に見えるので、これだと逆に条件がきつくなりすぎる気もする。
これはそのうち検証してみよう、暇があったら。
まあAWSのS3と違ってグローバルレベルでのバケット名の重複をほとんど気にしなくていい(そのテナント内なら用途別に自分の裁量で重複しないようにいくらでも作れる)から、「データ受信専用のバケット」を作っておいて、そこに入ってくるオブジェクト全てを処理対象にする(それ以外の用途ではそのバケットを利用しない)、というような処理構成を組めなくもないな、とは思った。
その点AWSのS3とはちょっと違うのかもしれない。
まあでもprefixの指定は欲しいよねやっぱり。。
(12)実行
さて、いざ実行である。
適当に以下のようなファイルを作る。
ID,NAME ID,NAME 1,test01 2,test02 3,test03 4,テスト太郎 5,test5 6,test6 7,テストセブン
これをoci cliでObject StorageにPUTする。
> oci os object put --namespace-name nxxxxxxxxxxx --bucket-name (3)で作ったバケット --name testdata01.csv
functionのメトリックを見てみる。
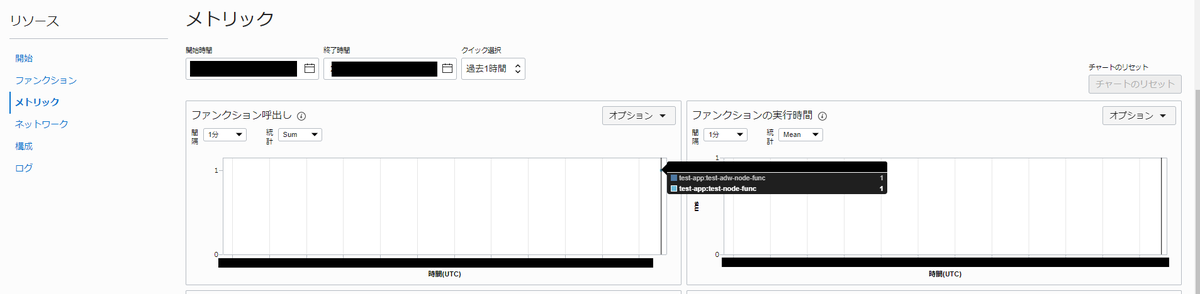
なんか実行されたのが確認できた。
2つの関数名が表示されているが、1つは私のテスト用なので無視してください。
逆に言うと1つのイベントで複数の関数を起動できることの証明でもあるが。
ちなみにここでエラーになると4つあるグラフのうち左下のグラフ(ファンクション・エラーという表題のグラフ)にぽつんと点が浮かび上がる(´・ω・`)
ファンクションのメトリック画面は、「ファンクションが呼ばれたか」「どれくらいの処理時間だったか」「エラーだったか」等をパッと見で捉えることができる画面である。
逆に言うとこれ以上細かいことはこの画面からはわからない。
特にエラーになったときが困るのだが、そういうためにロギング設定は必須である。
ここでログを見てみる。
(10)でつくったログを選択すると直近5分を初期の検索条件にログが検索される。
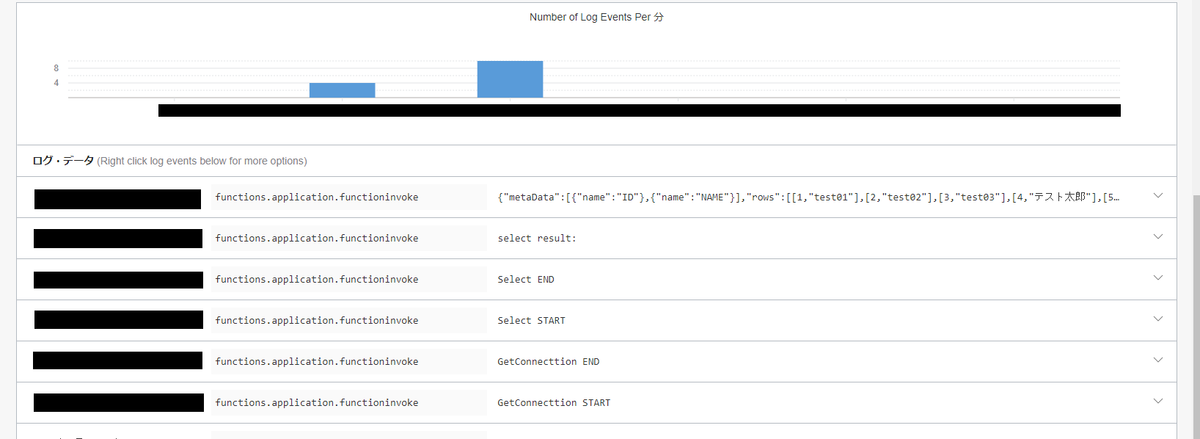
ちゃんと動いたっぽい。
AWS Lambdaのログ出力先となるCloudWatchと同じで、console.logで出力した内容も見えている。
登録後のselectで結果もかえってきているようだ。
なお、ロギングへのログ出力は、CloudWatchと同様で、実行後すぐには反映されない。
Functionの場合、処理が完全に終了するまでは反映されないようだ(未確認。実体験からの予想)
出てこなければちょっと待ってみた方が良い。
最後にDBを覗いてみる。

ちゃんと入ったようだ。
成功!
おわりに
正直に言うと語りたかったのは(6)の部分がメインだったのだが他との連携の関連でいろいろ膨らんでしまった。
そういう意味でも今回、いろいろ試行錯誤したのも(6)の部分が主だった。
Docker難しい。。。
まあ、全体的な流れを一通り包括できたのは良かったと思うし、自分の中での知識の整理にもなったと思うので、OKとしよう。